당뇨병은 세계 성인 인구의 9%이상에 영향을 미치고 있으며, 점점 더 증가하고 있다.
이번 목적은 30일 이내에 재입원해야 하는 환자를 예측하는 모델을 생성하는 것이다.
병원에서 중증 환자의 모니터링, 조기예약, 간호사 호출과 같은 예방 조치를 더 많이 취할 수 있다면
더 많은 생명을 구할 수 있는 일이 될수도 있을것이다.
1. 데이터 준비
(1) 데이터 로드
# openml API를 사용하여 당뇨 환자 데이터 읽어오기
from sklearn.datasets import fetch_openml
X_orig, y = fetch_openml(data_id=43874, as_frame=True, return_X_y=True)(2) 데이터 확인
X_orig.info()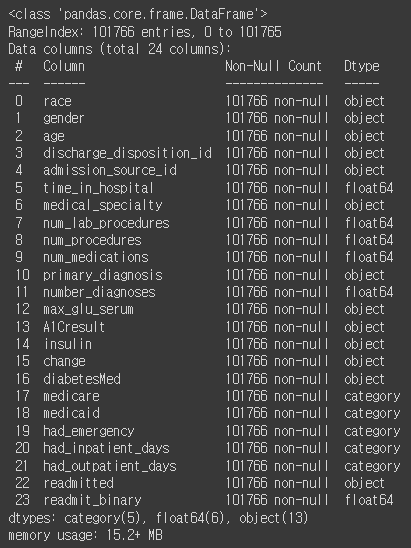
# 각 컬럼별로 값을 실제로 확인해본다.
X_orig.sample(n=5)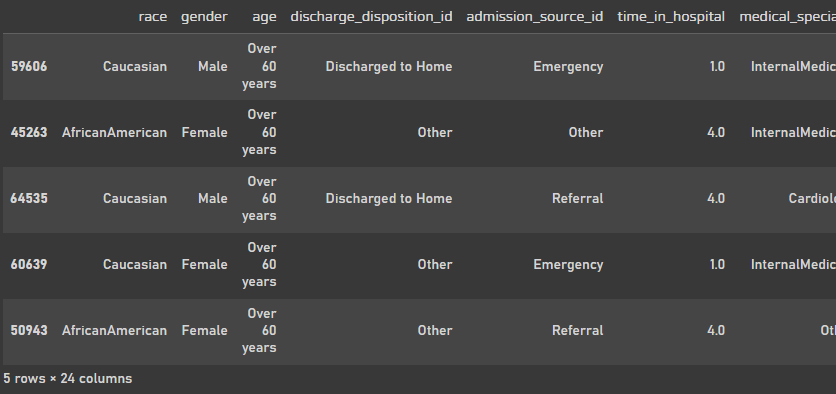
2. 데이터 전처리 및 EDA
(1) 라이브러리 설치 및 패키지 import
!pip install lightgbm optuna shap --quietimport math
import os
import numpy as np
import pandas as pd
pd.set_option('display.max_columns',50)
pd.set_option('display.max_rows',50)
from sklearn.preprocessing import OneHotEncoder
from sklearn.model_selection import train_test_split
from sklearn import metrics
import lightgbm as lgb
import optuna
import shap
from IPython.display import Markdown, display
import matplotlib.pyplot as plt
import seaborn as sns이번 데이터분석에는 lightgbm을 사용하였습니다:D
(2) Target 유의 변수 제거
# Target 변수와 상관관계가 높은 feature 2개를 제거한다
X_orig['readmitted'].value_counts()>> NO 54864
>30 35545
<30 11357
Name: readmitted, dtype: int64
X_orig['readmit_binary'].value_counts()>> 0.0 54864
1.0 46902
Name: readmit_binary, dtype: int64
# Actual Target
y.value_counts()>> 0.0 90409
1.0 11357
Name: readmit_30_days, dtype: int64
위에서 보면 알 수 있듯이 2개의 변수는 y와 직접적으로 상관관계가 보이므로 학습 Feature에 사용할 수 없다.
y와 직접적으로 상관관계가 있는 변수를 feature로 사용할 경우, 모든 경우에 100%에 가까운 정확도를 보이게 되며
이는 정답을 보여주는 것과 같기 때문에 정상적인모델이라고 할 수 없다.
(3) 인코딩을 통한 데이터 준비
# 인코딩을 위한 함수 정의
def transform_data(X_):
# Remove alternative target columns
X = X_.drop(['readmitted', 'readmit_binary'], axis=1)
# Binary encode boolean columns
bool_cols_l = X.select_dtypes(include=["category"]).columns.tolist()
X[bool_cols_l] = X[bool_cols_l].astype(str).replace({"True":1, "False":0})
print(bool_cols_l)
# One hot encode categorical columns
cat_cols_l = X.select_dtypes(include=["object"]).columns.tolist()
print(cat_cols_l)
ohe = OneHotEncoder(handle_unknown='ignore', sparse=False)
ohe_np = ohe.fit_transform(X[cat_cols_l].astype("category"))
X[ohe.get_feature_names_out(cat_cols_l)] = ohe_np.astype(int)
# Drop original categorical columns
X.drop(cat_cols_l, axis=1, inplace=True)
return X원핫인코딩을 통해 오브젝트(문자열)열을 카테고리로 나눠준다
X = transform_data(X_orig)
# 변경전 feature 갯수
print(f"Number of Features: {len(X_orig.columns)}")
print(X_orig.columns)
# 인코딩후 feature 갯수
print(f"Number of Features(After processing): {len(X.columns)}")
print(X.columns)

24개였던 feature갯수가 54개로 늘어났다
(4) 데이터셋 분할
rand = 42
os.environ['PYTHONHASHSEED']=str(rand)
np.random.seed(rand)classes_l = ['NO or > 30 days', '< 30 days']
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.7, random_state=rand)
X_orig_test = X_orig.loc[X_test.index]30일 이전 방문자와 30일 이후 방문자로 클래스를 나눠서 데이터셋을 구성하였다.
(5) Evaluation 함수 정의
자주 사용해서 수치와 그래프를 나타내기 위해서 함수를 작성해준다
def evaluate_class_mdl(fitted_model, X_train, X_test, y_train, y_test, plot=True, pct=True, thresh=0.5):
y_train_pred = fitted_model.predict(X_train).squeeze()
if len(np.unique(y_train_pred)) > 2:
y_train_pred = np.where(y_train_pred > thresh, 1, 0)
y_test_prob = fitted_model.predict(X_test).squeeze()
y_test_pred = np.where(y_test_prob > thresh, 1, 0)
else:
y_test_prob = fitted_model.predict_proba(X_test)[:,1]
y_test_pred = np.where(y_test_prob > thresh, 1, 0)
roc_auc_te = metrics.roc_auc_score(y_test, y_test_prob)
cf_matrix = metrics.confusion_matrix(y_test, y_test_pred)
tn, fp, fn, tp = cf_matrix.ravel()
acc_tr = metrics.accuracy_score(y_train, y_train_pred)
acc_te = metrics.accuracy_score(y_test, y_test_pred)
pre_te = metrics.precision_score(y_test, y_test_pred)
rec_te = metrics.recall_score(y_test, y_test_pred)
f1_te = metrics.f1_score(y_test, y_test_pred)
mcc_te = metrics.matthews_corrcoef(y_test, y_test_pred)
if plot:
print(f"Accuracy_train: {acc_tr:.4f}\t\tAccuracy_test: {acc_te:.4f}")
print(f"Precision_test: {pre_te:.4f}\t\tRecall_test: {rec_te:.4f}")
print(f"ROC-AUC_test: {roc_auc_te:.4f}\t\tF1_test: {f1_te:.4f}\t\tMCC_test: {mcc_te:.4f}")
plt.figure(figsize=(6, 5))
if pct:
ax = sns.heatmap(cf_matrix/np.sum(cf_matrix), annot=True,\
fmt='.2%', cmap='Blues', annot_kws={'size':16})
else:
ax = sns.heatmap(cf_matrix, annot=True,\
fmt='d',cmap='Blues', annot_kws={'size':16})
ax.set_xlabel('Predicted', fontsize=12)
ax.set_ylabel('Observed', fontsize=12)
plt.show()
return y_train_pred, y_test_prob, y_test_pred
else:
t = cf_matrix.sum()
metrics_dict = {'accuracy_train':acc_tr , 'accuracy_test':acc_te, 'precision':pre_te, 'recall':rec_te,\
'roc_auc':roc_auc_te, 'f1':f1_te, 'mcc': mcc_te, 'tn%':tn/t, 'fp%':fp/t, 'fn%':fn/t, 'tp%':tp/t }
return metrics_dictconfusion matrix를 수치와 히트맵으로 보기좋기 찍어주기 위해서 함수 작성
(6) Base 모델 학습
%matplotlib inline
clf = lgb.LGBMClassifier(random_state=rand, n_jobs=-1, verbose=-1)
clf.fit(X_train, y_train)
_ = evaluate_class_mdl(clf, X_train, X_test, y_train, y_test)
숫자만 봤을 때는 정확도는 매우 높은 것으로 보이지만, Precision과 Recall은 매우 낮아 전반적인 성능은 나쁘다.
구글 코랩 환경에서 진행했는데 lgb를 사용할때 verbose=-1을 넣어주지 않으면
[LightGBM] [Warning] Found whitespace in feature_names, replace with underlines [LightGBM] [Info] Number of positive: 7932, number of negative: 63304 [LightGBM] [Info] Auto-choosing row-wise multi-threading, the overhead of testing was 0.095156 seconds. You can set `force_row_wise=true` to remove the overhead. And if memory is not enough, you can set `force_col_wise=true`. [LightGBM] [Info] Total Bins 319 [LightGBM] [Info] Number of data points in the train set: 71236, number of used features: 53 [LightGBM] [Info] [binary:BoostFromScore]: pavg=0.111348 -> initscore=-2.077043 [LightGBM] [Info] Start training from score -2.077043
위와같은 경고 메시지가 출력되었다. verbose=-1 을 넣어주니 경고메시지 없이 잘 출력된다!
(7) Class Weight
모델은 기본적으로 Positive 클래스를 예측할 때 보수적 접근 방법으로 모델을 생성하기 떄문에 너무 많은 위험을 감수하지 않는다. 해결책은 Positive 클래스에 더 많은 비중을 두도록 강제하는 Hyperparameter를 활용하는 것이다.
클래스 가중치를 부여할 수 있는 방법은 여러 가지가 있지만, 그 중 하나인 scale_pos_weight를 활용해보자.
보통 많이 사용하는 값은 아래 수식을 통해 계산한다.
number of negative samples / number of positive sample
def_scale_pos_weight = len(y[y==0]) / len(y[y==1])
print(f"default scale pos weight: {def_scale_pos_weight:.2f}")>> default scale pos weight: 7.96
clf = lgb.LGBMClassifier(random_state=rand, n_jobs=-1, verbose=-1, scale_pos_weight=def_scale_pos_weight)
clf.fit(X_train, y_train)
_ = evaluate_class_mdl(clf, X_train, X_test, y_train, y_test)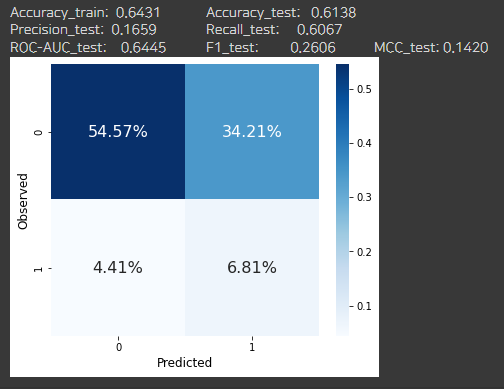
실제로 모델의 성능을 향상시키기는 하지만 아직 상당한 수준의 오탐지가 존재한다.
clf = lgb.LGBMClassifier(random_state=rand, n_jobs=-1, verbose=-1, scale_pos_weight=def_scale_pos_weight*2)
clf.fit(X_train, y_train)
_ = evaluate_class_mdl(clf, X_train, X_test, y_train, y_test)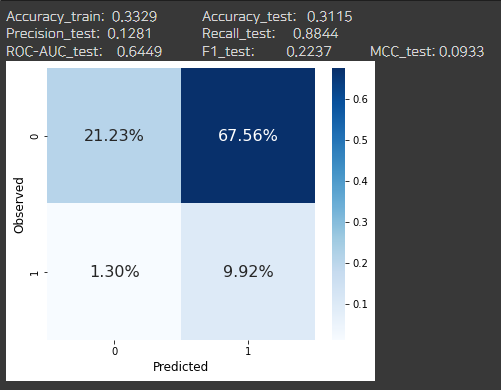
scale_pos_weight를 두배해줬더니 오탐지가 두배가 되었다,,,
clf = lgb.LGBMClassifier(random_state=rand, n_jobs=-1, verbose=-1, scale_pos_weight=def_scale_pos_weight/2)
clf.fit(X_train, y_train)
_ = evaluate_class_mdl(clf, X_train, X_test, y_train, y_test)
반대로 절반으로 줄였더니 모델이 많이 보수적으로 바뀌었다
(8) Hyperparameter tuning
보수적 접근 방법은 다음과 같은 특징 때문에 실제 적용이 너무 어렵다.
1. True Positive(정탐)만 Maximize
2. False Positive(미탐) 최소화
3. 보통은 Recall이나 Precision을 더 선호
4. 미탐보다 오탐이 훨씬 더 많음
현재 모델의 결과를 보면, 거의 모든 것이 Positive 클래스에 속할 것으로 예상되는 문제가 있다.
이를 해결하기 위해 몇 가지 제약 조건을 정의해야 한다. 예를 들어, 재입원하지 않은 모든 데이터을 포함할 수 있도록 적어도 충분한 true negative가 있어야한다.
min_tn = X_orig[X_orig['readmitted']=='NO'].shape[0] / X_orig.shape[0]
print(f"Patients % that never readmitted (Minimum % of True Negatives): {min_tn:.2%}")>> Patients % that never readmitted (Minimum % of True Negatives): 53.91%
+ 30일이 지나서 재입원한 환자도 False Positive에 포함되도록 비율을 조정해야한다.
max_fp = X_orig[X_orig['readmitted']=='>30'].shape[0] / X_orig.shape[0]
print(f"Patients % that were readmitted over 30 days later (Maximum % of False Positives): {max_fp:.2%}")>> Patients % that were readmitted over 30 days later (Maximum % of False Positives): 34.93%
def optimize_lgb(trial):
params = {
'max_depth': trial.suggest_int('max_depth', 2, 11),
'scale_pos_weight': trial.suggest_float('scale_pos_weight', def_scale_pos_weight/2, def_scale_pos_weight*2),
'reg_lambda': trial.suggest_float('reg_lambda', 1e-8, 10.0, log=True),
'reg_alpha': trial.suggest_float('reg_alpha', 1e-8, 10.0, log=True)
}
if params['max_depth'] == 11:
params['max_depth'] = -1
clf = lgb.LGBMClassifier(random_state=rand, n_jobs=-1, verbose=-1, **params)
clf.fit(X_train, y_train)
metrics_dict = evaluate_class_mdl(clf, X_train, X_test, y_train, y_test, plot=False)
if (metrics_dict['tn%'] < min_tn) or (metrics_dict['fp%'] > max_fp):
return 0
return metrics_dict['recall']함수에서 scale_pos_weight를 사용한 클래스 가중치 외에도 max_depth(트리 깊이를 제한하기 위해) 및
reg_lambda 및 reg_alpha를 사용한 L1/L2 정규화에 대한 최상의 하이퍼파라미터를 찾습니다.
이렇게 하면 모델이 일반화되는 데 도움이 됩니다. 목적 함수는 두 제약 조건이 충족되지 않는 경우를 제외하고 recall을 출력합니다.
이 경우 0을 반환합니다.
%%time
opt_study = optuna.create_study(direction='maximize')
opt_study.optimize(optimize_lgb, n_trials=100)
optuna를 사용하여 최상의 하이퍼파라미터를 찾아준다.
best_params = opt_study.best_params
print(best_params)>> {'max_depth': 9, 'scale_pos_weight': 7.916633439164792, 'reg_lambda': 0.4065568554562682, 'reg_alpha': 4.780027134366964}
best_params = {'max_depth': 9, 'scale_pos_weight': 7.916633439164792, 'reg_lambda': 0.4065568554562682,\
'reg_alpha': 4.780027134366964}%matplotlib inline
clf = lgb.LGBMClassifier(random_state=rand, n_jobs=-1, verbose=-1, **best_params)
clf.fit(X_train, y_train)
_, y_prob, y_pred = evaluate_class_mdl(clf, X_train, X_test, y_train, y_test)
class weight를 줬을때와 비슷한 성능이 나오고 있다.
3. 에러 분석
(1) 현재까지의 결과가 최선일까?
Confusion Matrix를 자세히 살펴보면 False Positive보다 True Positive가 60% 더 많지만 False Positive가 결과적으로 더 심각한 비용을 발생시킨다. 그러나 우리가 설정한 제약으로 인해 True Positive의 절반 이상이 결국 재입원으로 분류될 것다.
X_orig_test['readmitted'].value_counts()>> NO 16461
>30 10644
<30 3425
Name: readmitted, dtype: int64
대부분의 모델 목표가 30일 이상 재입원을 예상하므로 긍정적인 클래스가 이 그룹을 독점적으로 나타낸다. 30일 이상 재입원 하지 않은 것에 대한 False Positive 오분류는 NO 에 대한 오분류만큼 나쁘지 않다. 그렇다면 30일 이후 재입원에 대한 오탐지 비율은 얼마나될까?
preds_df = pd.DataFrame({'readmitted':X_orig_test['readmitted'],\
'y_true':y_test.astype(int),\
'y_pred':y_pred})
preds_df[(preds_df.y_true==0) & (preds_df.y_pred==1)].value_counts(normalize=True)>> readmitted y_true y_pred
NO 0 1 0.504103
>30 0 1 0.495897
dtype: float64
실제로 오탐지의 거의 절반(전체 테스트 샘플의 34.72%)이 결국 재입원하였으므로 사전 예방 조치를 취하는 것이 나쁜 것이 아니라고 판단된다. 고려해야 할 잘못된 결과는 나머지 절반에 대한 부분이다.
(2) Error를 주제 그룹으로 나눠보자
def set_header_font():
return [dict(selector="th", props=[("font-size", "14pt")])]
def metrics_by_group(s):
accuracy = metrics.accuracy_score(s.y_true, s.y_pred) * 100
precision = metrics.precision_score(s.y_true, s.y_pred) * 100
recall = metrics.recall_score(s.y_true, s.y_pred) * 100
f1 = metrics.f1_score(s.y_true, s.y_pred) * 100
roc_auc, fnr, fpr = np.nan, np.nan, np.nan
if len(np.unique(s.y_true)) == 2:
roc_auc = metrics.roc_auc_score(s.y_true, s.y_prob) * 100
tn, fp, fn, tp = metrics.confusion_matrix(s.y_true, s.y_pred).ravel()
fnr = (fn/(tp+fn)) * 100
fpr = (fp/(tn+fp)) * 100
support = len(s.y_true)
return pd.Series((support, accuracy, precision, recall, f1, roc_auc, fnr, fpr),\
index=['support', 'accuracy', 'precision', 'recall', 'f1', 'roc-auc', 'fnr', 'fpr'])
def error_breakdown_by_group(mdl, y_true, y_prob, y_pred, orig_df, group_col, exclude_groups=None):
print(f"Error breakdown for group '{group_col}'")
predict_df = pd.DataFrame({group_col: orig_df[group_col].tolist(),\
'y_true': y_true,
'y_pred': y_pred,
'y_prob': y_prob}, index=y_true.index)
if exclude_groups is not None:
predict_df = predict_df[~predict_df[group_col].isin(exclude_groups)]
group_metrics_df = predict_df.groupby([group_col]).apply(metrics_by_group)
html = group_metrics_df.sort_values(by='support', ascending=False).style.\
format({'support':'{:,.0f}', 'accuracy':'{:.1f}%', 'precision':'{:.1f}%', 'recall':'{:.1f}%',\
'f1':'{:.1f}%', 'roc-auc':'{:.1f}%', 'fnr':'{:.1f}%', 'fpr':'{:.1f}%'}).\
set_properties(**{'font-size': '13pt'}).set_table_styles(set_header_font()).\
highlight_max(subset=['accuracy','precision','recall','f1','roc-auc']).\
highlight_min(subset=['fnr','fpr'])
return html
def compare_confusion_matrices(y_true_1, y_pred_1, y_true_2, y_pred_2, group_1, group_2,\
plot=True, compare_fpr=False):
conf_matrix_1 = metrics.confusion_matrix(y_true_1, y_pred_1)
conf_matrix_2 = metrics.confusion_matrix(y_true_2, y_pred_2)
if plot:
fig, ax = plt.subplots(1,2,figsize=(12,5))
sns.heatmap(conf_matrix_1/np.sum(conf_matrix_1), annot=True,\
fmt='.2%', cmap='Blues', annot_kws={'size':16}, ax=ax[0])
ax[0].set_title(group_1 + ' Confusion Matrix', fontsize=14)
ax[0].set_xlabel('Predicted', fontsize=12)
ax[0].set_ylabel('Observed', fontsize=12)
sns.heatmap(conf_matrix_2/np.sum(conf_matrix_2), annot=True,\
fmt='.2%', cmap='Blues', annot_kws={'size':16}, ax=ax[1])
ax[1].set_title(group_2 + ' Confusion Matrix', fontsize=14)
ax[1].set_xlabel('Predicted', fontsize=12)
ax[1].set_ylabel('Observed', fontsize=12)
plt.show()(2)-1. 인구통계 정보를 통한 분석(나이)
error_breakdown_by_group(clf, y_true=y_test, y_prob=y_prob, y_pred=y_pred, orig_df=X_orig_test, group_col='age')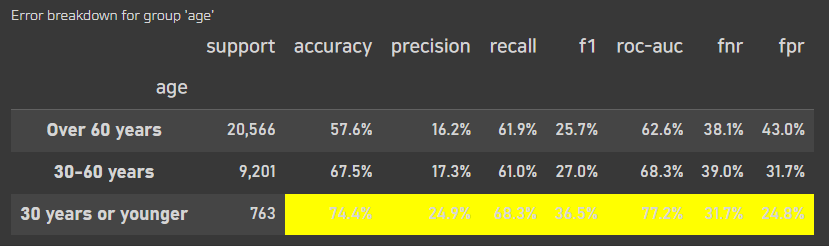
전체 데이터로 봤을때는 성능이 좋지 못한 모델이었으나,
나이로 나누어서 30대 이전의 그룹은 좋은 성능을 보이고 있는것을 확인 할 수 있다.
(2)-2. 인구통계 정보를 통한 분석(성별, 성별미상 제외)
error_breakdown_by_group(clf, y_true=y_test, y_prob=y_prob, y_pred=y_pred, orig_df=X_orig_test, group_col='gender',\
exclude_groups=['Unknown/Invalid'])
남성의 경우가 좀더 성능이 좋아보이지만
성별에 따라서는 크게 성능차이를 보이고 있지 않다.
_ = compare_confusion_matrices(y_test[X_test['gender_Male']==1], y_pred[X_test['gender_Male']==1],\
y_test[X_test['gender_Female']==1], y_pred[X_test['gender_Female']==1],\
'Male', 'Female')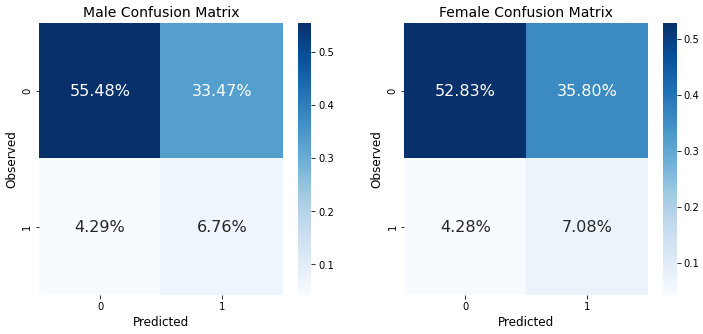
confusion matrix를 사용해서 같이 찍어보면 성능차이 비교가 쉬워진다.
(2)-3. 의학적 특징을 통한 분석
error_breakdown_by_group(clf, y_true=y_test, y_prob=y_prob, y_pred=y_pred, orig_df=X_orig_test, group_col='admission_source_id')
도메인 지식이 충분하지 않으나, 의학적 지식으로 분석을 해보았을때 응급환자의 경우에 성능이 가장 좋게 확인 되었다.
error_breakdown_by_group(clf, y_true=y_test, y_prob=y_prob, y_pred=y_pred, orig_df=X_orig_test, group_col='had_inpatient_days')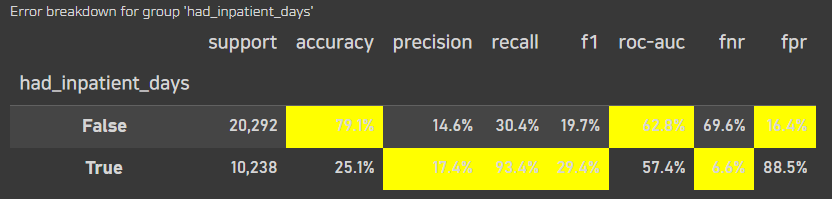
또한, 통증기간이 있었을때의 경우도 성능이 꽤나 좋게 나온것을 확인 할 수 있었다.
_ = compare_confusion_matrices(y_test[X_test['had_inpatient_days']==0], y_pred[X_test['had_inpatient_days']==0],\
y_test[X_test['had_inpatient_days']==1], y_pred[X_test['had_inpatient_days']==1],\
'No Inpatient Days', 'Inpatient Days', compare_fpr=True)
히트맵으로 봤을때 뚜렷하게 차이를 확인 할 수 있다.
# 30일 이후 재입원을 포함하지 않는 하위 집합의 confusion matrix
_ = compare_confusion_matrices(y_test[(X_test['had_inpatient_days']==0) & (X_orig_test['readmitted']!='>30')], y_pred[(X_test['had_inpatient_days']==0) & (X_orig_test['readmitted']!='>30')],\
y_test[(X_test['had_inpatient_days']==1) & (X_orig_test['readmitted']!='>30')], y_pred[(X_test['had_inpatient_days']==1) & (X_orig_test['readmitted']!='>30')],\
'No Inpatient Days w/o >30', 'Inpatient Days w/o >30', compare_fpr=True)
통증이 있는 사람들이 30일 이전에 재입원을 하는 예측 모델이 지금까지 중 가장 성능이 좋게 나왔다
4. 주제 그룹 분석
(1) Sample data
X_test_sample = X_test[(X_orig_test['readmitted']!='>30')].sample(frac=0.1)
y_test_sample = y_test.loc[X_test_sample.index]
y_prob_sample = clf.predict_proba(X_test_sample)[:,1]
y_pred_sample = np.where(y_prob_sample > 0.5, 1, 0)(2) SHAP values 생성하기
SHAP values는 주요 특성을 추출하거나 비교하기 위해 사용하면 좋다.
%%time
shap_explainer = shap.Explainer(clf, X_train)
shap_values = shap_explainer(X_test_sample)
shap_values.values
(3) Feature Importance Plots
한 축에서 SHAP 값의 절대값을 평균화하면 기능 중요도 측정값(Feature당 하나)
np.abs(shap_values.values).mean(axis=0)
# 각 Feature의 Importance 순위 표시
shap.plots.bar(shap_values, max_display=15)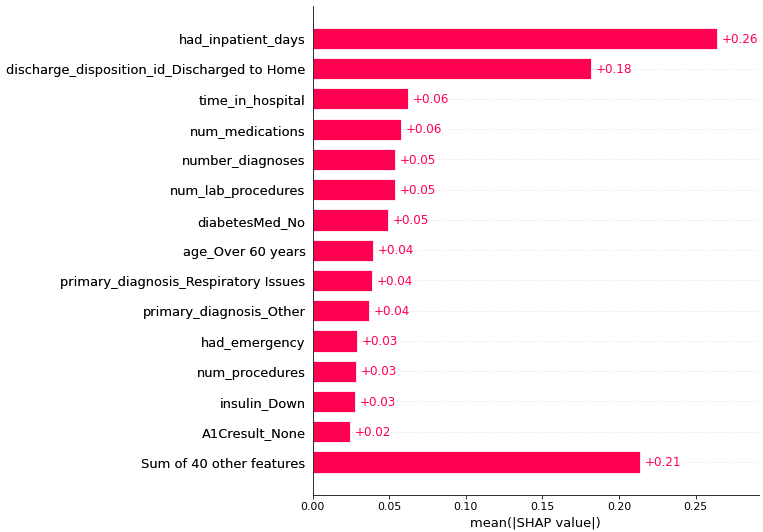
shap.plots.beeswarm(shap_values, max_display=15)
shap values를 통해서 모델에 사용할 feature를 선택하기에 유용하다.
(4) Scatter Plots
가장 중요도가 높은 'had_inpatient_days' feature와 다른 feature간의 상관성을 확인하자
shap.plots.scatter(shap_values[:,"time_in_hospital"],\
color=shap_values[:,"had_inpatient_days"])
shap.plots.scatter(shap_values[:,"num_medications"],\
color=shap_values[:,"had_inpatient_days"])
shap.plots.scatter(shap_values[:,"num_lab_procedures"],\
color=shap_values[:,"had_inpatient_days"])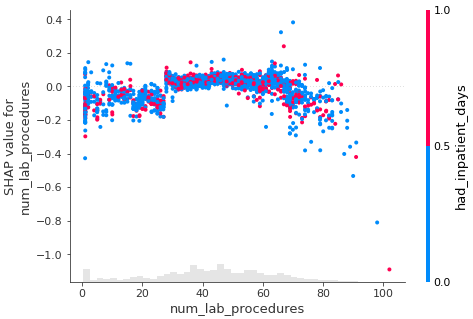
shap.plots.scatter(shap_values[:,"num_procedures"],\
color=shap_values[:,"had_inpatient_days"])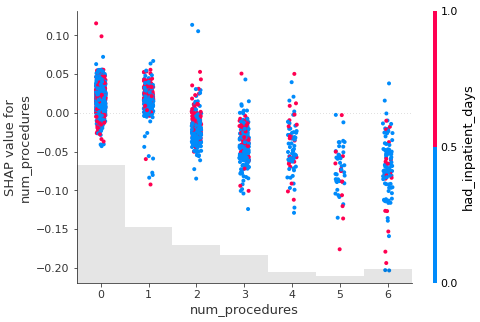
shap.plots.scatter(shap_values[:,"number_diagnoses"], color=shap_values[:,"had_inpatient_days"])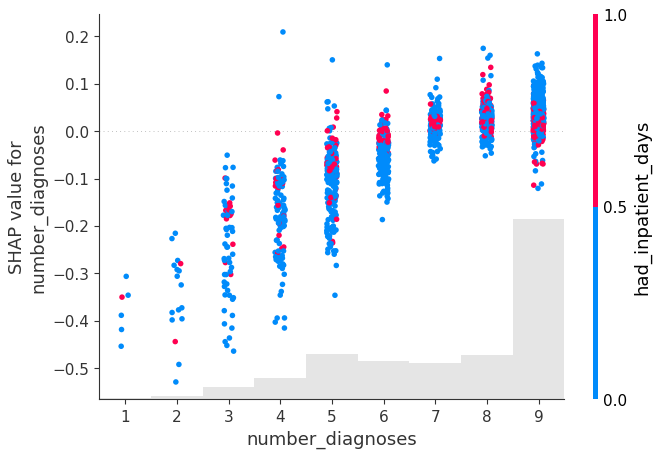
해당 지표들을 통해서 모델에 사용한 feature의 선택이유를 설명할 수도 있다.
5. 에러를 줄이는 몇 가지 전략
(1) Post-processing (predictions)
Positive 클래스를 예측하는 경우에 대한 임계값 조절하는 것은 일반적인 일이다.
임계값이 일관되게 0.5일 필요는 없다. 에러를 최소화하기 위해 확률 자체를 보정하는 경우도 있다.
preds_df = pd.DataFrame({'readmitted':X_orig_test['readmitted'],\
'had_inpatient_days':X_test['had_inpatient_days'],\
'y_true':y_test.astype(int),\
'y_pred':y_pred,
'y_prob':y_prob})
preds_df = preds_df[(preds_df['readmitted']!='>30')]
preds_df['y_pred_new'] = np.where(preds_df.had_inpatient_days==0,\
np.where(preds_df.y_prob > 0.45, 1, 0),
np.where(preds_df.y_prob > 0.59, 1, 0))_ = compare_confusion_matrices(preds_df.loc[preds_df.had_inpatient_days==0, 'y_true'],\
preds_df.loc[preds_df.had_inpatient_days==0, 'y_pred'],\
preds_df.loc[preds_df.had_inpatient_days==0, 'y_true'],
preds_df.loc[preds_df.had_inpatient_days==0, 'y_pred_new'],
'No Inpatient Days .5 threshold', 'No Inpatient Days .45 threshold')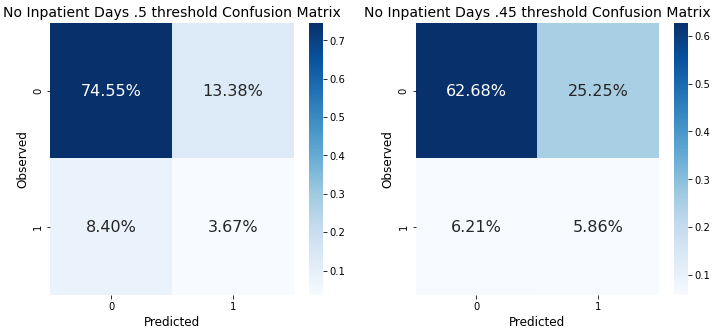
_ = compare_confusion_matrices(preds_df.loc[preds_df.had_inpatient_days==1, 'y_true'],\
preds_df.loc[preds_df.had_inpatient_days==1, 'y_pred'],\
preds_df.loc[preds_df.had_inpatient_days==1, 'y_true'],
preds_df.loc[preds_df.had_inpatient_days==1, 'y_pred_new'],
'Inpatient Days .5 threshold', 'Inpatient Days .59 threshold')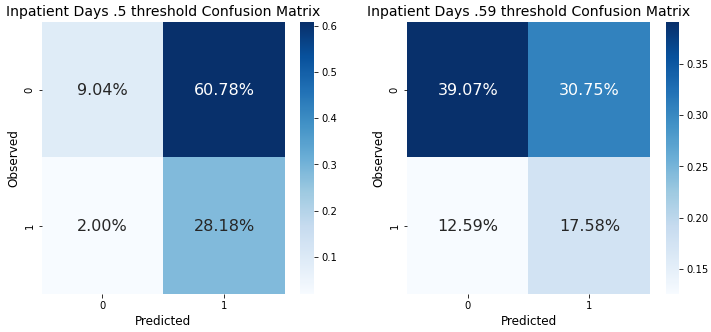
이 모델에서는 크게 차이가 없거나, 더 나빠지기도 했지만 임계값을 조절하는 것만으로도 성능차이가 비교가 된다.
(2) In-processing (model)
- sample_weight 혹은 다양한 sampling 기법을 사용하여 모델이 가장 못 맞추는 샘플에 더 집중하도록 한다.
- 코호트에 따라 False Negative를 다르게 패널티화하는 맞춤형 loss function 활용
- 대신 다중 클래스 분류 모델을 사용해보자. 아마도 NO와 >30을 분리하면 모델의 성능이 향상될 수 있다.
(3) Pre-Processing (data)
- 도메인 전문가와 함께 에러를 검토하고 더 잘 분류하는 데 도움이 될 수 있는 새로운 Feature를 찾아보는게 좋다.
- 이전에 엔지니어링된 일부 Feature가 특징을 잘 분류할 수 있는 특성이 엔지니어링 과정에서 사라졌을 수도 있다. 예를 들어 연령은 연령 그룹에 있지만 더 작은 그룹 또는 실제 연령으로 사용한다면 오류가 더 줄어들 것입니다. (대신 연산량이 많아짐)
데이터 분석가는 결과가 이렇구나 하지말고 항상 왜? 라는 의문을 가져야한다.
분석을 하면서 내가 변경한것이나 사용한것에는 이유가 있어야한다.
'개발새발 > 데이터분석' 카테고리의 다른 글
| [Python] 유방암 환자 분류 모델(Logistic Regression, KNN, LDA, SVM, Random Forest) (1) | 2024.01.27 |
|---|---|
| [Python] 공기질 데이터 분석(다양한 Regression) (0) | 2024.01.19 |
| [Python] 자녀와 엄마의 IQ 상관관계 분석(OLS Regression, K-fold cross validation) (0) | 2024.01.18 |
| [Python] youtube API를 활용한 동영상 및 채널 분석 (1) | 2024.01.15 |
| [Python] 의류판매량예측(시계열,RandomForest) (2) | 2024.01.13 |