영상 자료에서 추출할 수 있는 다양한 특성을 데이터로 변환하고, 양성 진단 환자와 음성 진단 환자의 특성을 학습하여 분류하고자 한다.
1. 데이터 로드 및 확인
(1) 라이브러리 import 및 데이터 로드
import numpy as np
import pandas as pd
import scipy.stats as stats
from time import time
from pprint import pprint
from IPython.display import Image
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="white")
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split, cross_val_score, GridSearchCV
from sklearn.metrics import classification_report, ConfusionMatrixDisplay
from sklearn.metrics import accuracy_score, precision_score, recall_score, roc_auc_score
from sklearn.metrics import f1_score, cohen_kappa_score, precision_recall_fscore_support
from sklearn.dummy import DummyClassifier
from sklearn.linear_model import LogisticRegressionCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.inspection import permutation_importance
import warnings
warnings.filterwarnings('ignore')
pd.set_option('display.max_columns',100)
pd.set_option('display.max_rows',100)
df = pd.read_csv('data/data.csv')
df.info()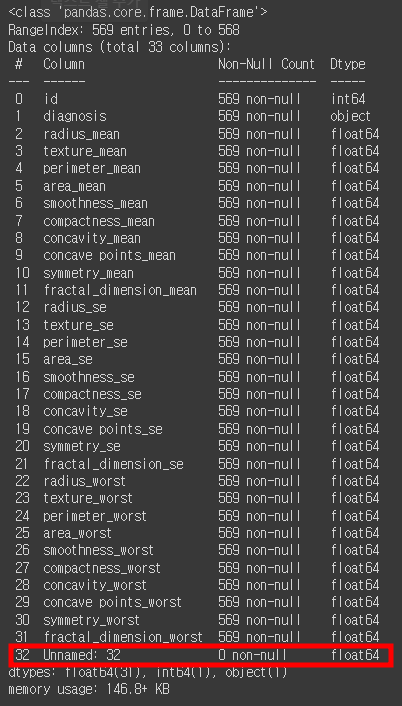
양성/음성 데이터만 object형이고 나머지는 float 형태의 데이터인것을 확인하였다.
그리고 마지막행에 데이터가 없는 열이 들어있는것을 확인
(2) 데이터 확인
df.shape>> (569, 33)
# 수치형 데이터를 가진 컬럼
df.select_dtypes(include=np.number).columns.tolist()
30개 정도야 눈으로 확인 할 수 있고 대부분이 float형태라 괜찮지만, feature가 많아지면 눈으로 확인하기 어려운점이 있다.
이때 수치형 feature만 뽑아서 확인할 수 도 있다.
# DataFrame의 describe 함수를 통해 수치형 컬럼의 통계량을 확인
df.describe()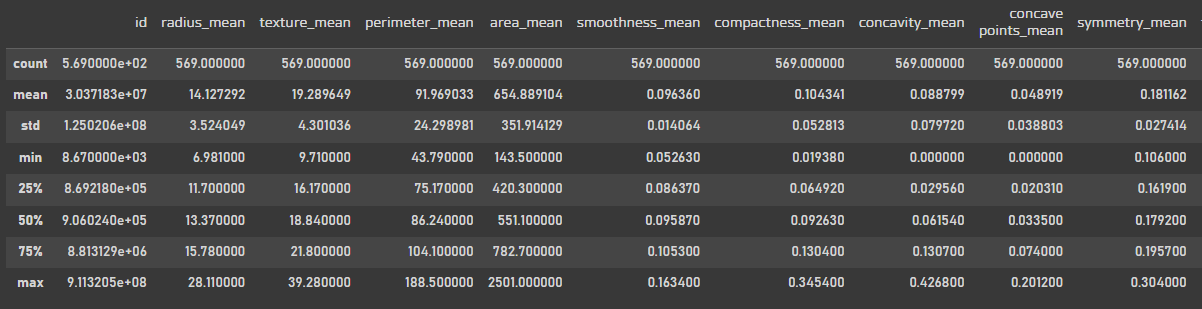

데이터를 로드했으면 항상 info, shape, describe 등 데이터를 확인하는것은 필수이다.
id는 환자를 나타내는 특성이기 때문에 무시하고, area_mean을 보면 min값과 max값의 차이가 많이나서 노이즈가 없는지 확인하는것이 좋을 것 같다. 여기서 평균값은 약 650정도로 min값에 좀 더 편향되어있을것이라고 예상해본다.
(3) 데이터 전처리
class_mapping = {'M': 'malignant', 'B': 'benign'}
df['diagnosis'] = df['diagnosis'].map(class_mapping)
df = df.drop('Unnamed: 32', axis=1)
df.head()
양성/음성을 진단하는 M과 B를 각각 바꿔주고, 마지막에 데이터가 아예 들어가있지 않았던 컬럼을 삭제해준다.
df.shape>> (569, 32)
컬럼이 하나 줄은것을 확인할 수 있다.
['{}: {}'.format(i, name) for (i, name) in enumerate(list(df.columns[2:]))]
환자를 나타내는 id값과 target값으로 사용할 diagnosis열을 빼고 인덱스를 새로 줬다
X = df.iloc[:, 2:].values
y = np.where(df['diagnosis'] == 'malignant', 1, 0)
print('Class labels:', np.unique(y), np.unique(df['diagnosis']),
[(i, val) for (i, val) in enumerate(np.bincount(y))])>> Class labels: [0 1] ['benign' 'malignant'] [(0, 357), (1, 212)]
object형으로 되어있는 diagnosis열을 1, 0으로 라벨을 따로 만들어서 사용해보자!
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1, stratify=y)print('Labels counts in y:', np.bincount(y),
[round(cnt / np.sum(np.bincount(y)) * 100, 1) for cnt in np.bincount(y)])
print('Labels counts in y_train:', np.bincount(y_train),
[round(cnt / np.sum(np.bincount(y_train)) * 100, 1) for cnt in np.bincount(y_train)])
print('Labels counts in y_test:', np.bincount(y_test),
[round(cnt / np.sum(np.bincount(y_test)) * 100, 1) for cnt in np.bincount(y_test)])
그리고 학습, 테스트 데이터셋으로 나누어주고 각각의 데이터셋이 같은 비율을 가지고 있는지도 확인해주었다.
(4) Data Readline check
data = pd.DataFrame(np.hstack((y_train.reshape(-1,1), X_train)),
columns=['target']+list(df.iloc[:, 2:].columns))
data.describe().T.round(2)
데이터를 그래프로 그려보기 위해서 전처리를 진행
target값은 0,1로 분리하였으니 mean값이 0.37인건 1인값이 37%정도가 된다는 의미
plt.subplots(figsize=(8,6))
sns.distplot(data.target, kde=False);
그래프로도 확인해보았다.
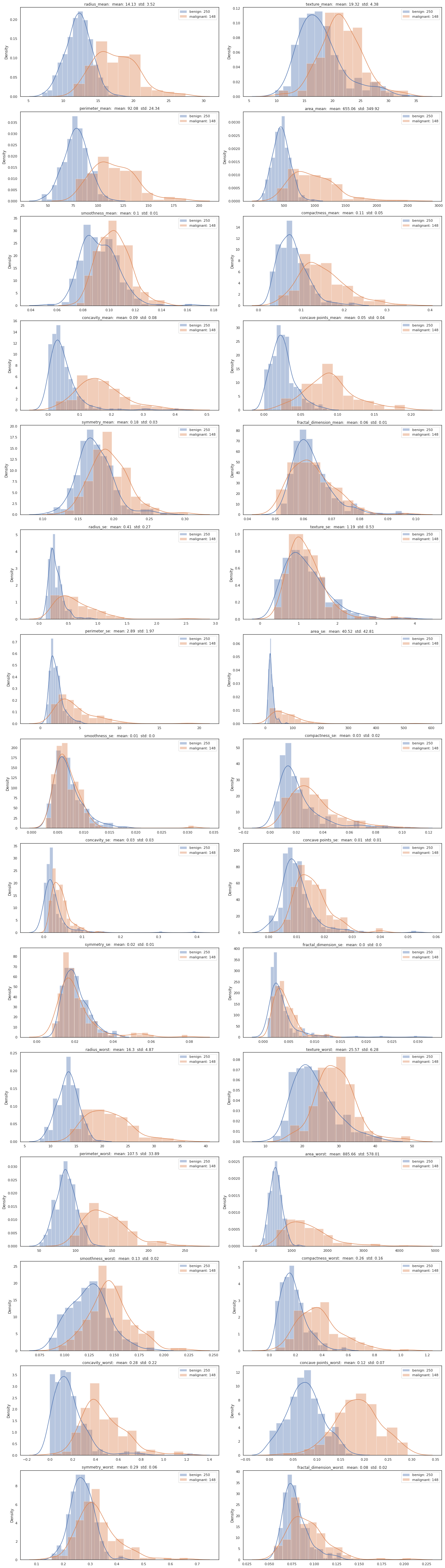
각각 feature 별로 살펴보았을때, 겹치는 부분이 많으면 양성,음성으로 판단하기 어려워 사용하기 좋지못한 feature라고 생각한다.
하지만 각각은 성능이 좋지 못하더라도 같이 사용했을 때 성능이 좋아질 수 있으니, 눈으로 참고정도만 하는게 좋다고 생각한다.
plt.figure(figsize=(30, 30))
matrix = np.triu(data.corr())
sns.heatmap(data.corr(),
annot=True, fmt='.2g',
mask=matrix,
vmin=-1, vmax=1, center=0,
cmap=sns.diverging_palette(20, 220, n=256));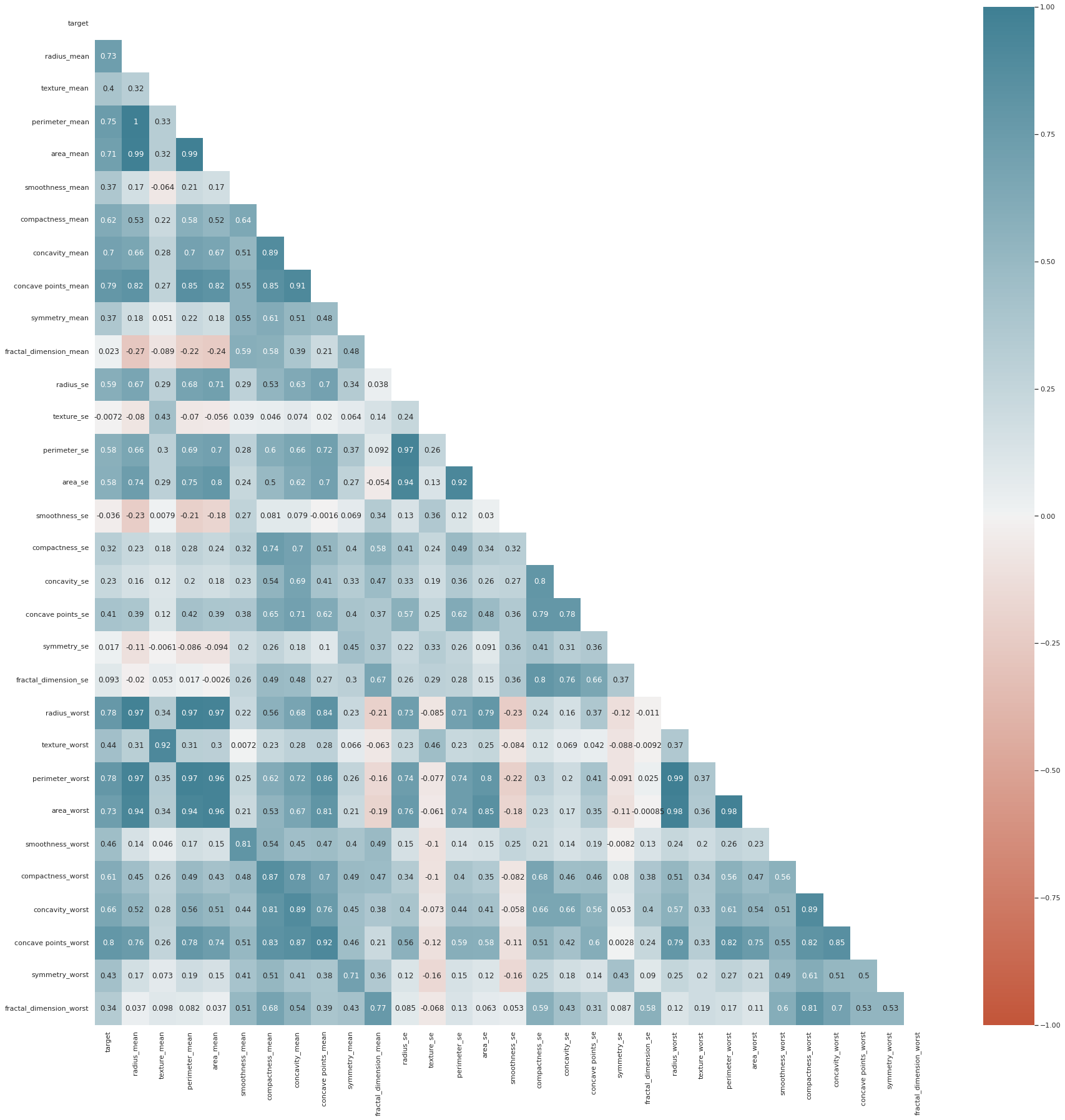
히트맵으로도 확인
그동안 feature가 많아도 20개정도였는데 30개 정도만 넘어가도 눈으로 바로 보기가 어려운듯 하다
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
sc.fit(X_train)
X_train_std = sc.transform(X_train)
X_test_std = sc.transform(X_test)위에서 확인했듯 area_mean같이 혼자만 수치가 큰 데이터가 있으면 모델 학습시 좋지 못한 영향을 끼치므로
스케일 조정을 해줬습니다.
f, axs = plt.subplots(15, 2, figsize=(20,70))
for i, feat in enumerate(X_train_std.T):
sns.distplot(feat[y_train==0], ax=axs.flat[i], label='{}: {}'.format(np.unique(df['diagnosis'])[0], len(y_train[y_train==0])))
sns.distplot(feat[y_train==1], ax=axs.flat[i], label='{}: {}'.format(np.unique(df['diagnosis'])[1], len(y_train[y_train==1])))
axs.flat[i].set_title('{}: mean: {} std: {}'.format(list(df.iloc[:, 2:].columns)[i], abs(feat.mean().round(2)), feat.std().round(2)))
axs.flat[i].legend()
plt.tight_layout()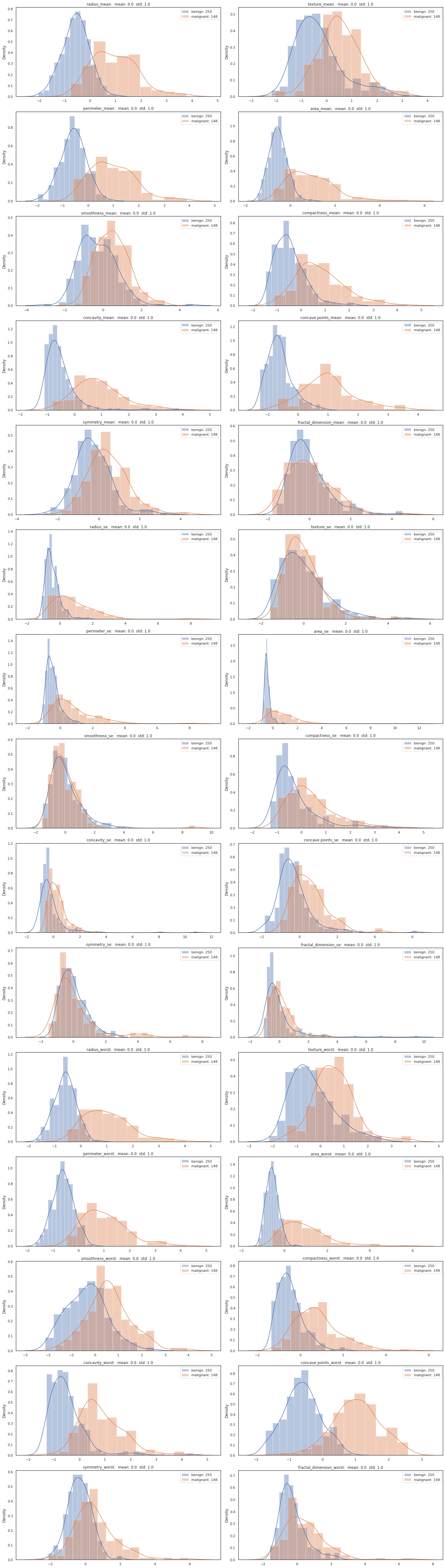
위에와 같은 수치의 데이터지만 mean은 0, std는 1로 조정된 정규분포를 얻을 수 있습니다.
2. Modeling
(1) DummyClassifier
from sklearn.dummy import DummyClassifier
from sklearn.model_selection import cross_val_score
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
from sklearn.metrics import classification_report
def get_cross_val(clf, X, y, model_name, cv_num=5, metric='f1'):
scores = cross_val_score(clf, X, y, cv=cv_num, scoring=metric)
mean = scores.mean()
std = scores.std()
p025 = np.quantile(scores, 0.025)
p975 = np.quantile(scores, 0.975)
metrics = ['mean', 'standard deviation', 'p025', 'p975']
s = pd.Series([mean, std, p025, p975], index=metrics) # np.where(lb < 0, 0, lb), np.where(ub > 1, 1, ub)
s.name = model_name
return s
def calculate_metrics(y_true, y_pred, duration, model_name, *args):
acc = accuracy_score(y_true, y_pred)
pre = precision_score(y_true, y_pred)
rec = recall_score(y_true, y_pred)
roc_auc = roc_auc_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
ck = cohen_kappa_score(y_true, y_pred)
p, r, fbeta, support = precision_recall_fscore_support(y_true, y_pred)
metrics = ['accuracy', 'precision', 'recall', 'roc_auc', 'f1_score', 'cohen_kappa',
'precision_both', 'recall_both', 'fbeta_both', 'support_both', 'time_to_fit (seconds)']
s = pd.Series([acc, pre, rec, roc_auc, f1, ck, p, r, fbeta, support, duration], index=metrics)
s.name = model_name
return s먼저 모델 결과를 나타내기 위해서 함수를 작성해줍니다.
d_clf = DummyClassifier(strategy='constant', constant=1)
d_clf.fit(X_train_std, y_train)
print('Accuracy (train): {:.2f}'.format(d_clf.score(X_train_std, y_train)))
print('Accuracy (test): {:.2f}'.format(d_clf.score(X_test_std, y_test)))
DummyClassifier는 덮어놓고 나는 1로 결과를 낸다는 의미
37%가 양성, 위에서 mean값이 37%였던것을 확인했었으니 맞다.
predictions = d_clf.predict(X_test_std)
cm = confusion_matrix(y_test, predictions)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=d_clf.classes_)
disp.plot()
y_pred = d_clf.predict(X_test_std)
print(classification_report(y_test, y_pred,
target_names=list(np.unique(df['diagnosis']))))
확인해보면 음성은 0% 양성은 37%
아무것도 하지않아도 37%정도의 정확도가 있음을 나타낸다.
(2) Logisitic Regression
로지스틱회귀모델은 target이 0,1로 나뉘어졌을 때 통상적으로 사용하는 모델이다.
from sklearn.linear_model import LogisticRegressionCV
lr_clf = LogisticRegressionCV(cv=5,
penalty='elasticnet', solver='saga',
Cs=np.power(10, np.arange(-3, 1, dtype=float)),
l1_ratios=np.linspace(0, 1, num=6, dtype=float),
max_iter=1000,
random_state=0)
start = time()
lr_clf.fit(X_train_std, y_train)
lr_duration = time() - start
print("LogisticRegressionCV took {:.2f} seconds for {} cv iterations with {} parameter settings.".format(lr_duration,
lr_clf.n_iter_.shape[1],
lr_clf.n_iter_.shape[2] * lr_clf.n_iter_.shape[3]))
print('Optimal regularization strength: {} Optimal L1 Ratio: {}'.format(lr_clf.C_[0], lr_clf.l1_ratio_[0]))
print('Accuracy (train): {:.2f}'.format(lr_clf.score(X_train_std, y_train)))
print('Accuracy (test): {:.2f}'.format(lr_clf.score(X_test_std, y_test)))
모델 선택을 할때 학습시간도 중요한 요소중에 하나이다
그래서 이번에는 학습시간도 같이 출력을 해보았다.
lr_params = dict(zip(list(df.iloc[:, 2:].columns), list(lr_clf.coef_[0])),
intercept=lr_clf.intercept_[0])
{param: value.round(2) for (param, value) in sorted(lr_params.items(), key=lambda item: item[1], reverse=True)}
각각 피쳐들이 어떻게 사용되었는지도 확인.
lr_cv = get_cross_val(lr_clf, X_test_std, y_test, 'logistic regression')
lr_cv.round(2)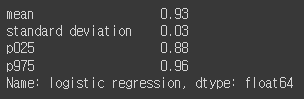
평균적으로 93%의 정확도가 나왔다.
predictions = lr_clf.predict(X_test_std)
cm = confusion_matrix(y_test, predictions)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=lr_clf.classes_)
disp.plot()
y_pred = lr_clf.predict(X_test_std)
print(classification_report(y_test, y_pred,
target_names=list(np.unique(df['diagnosis']))))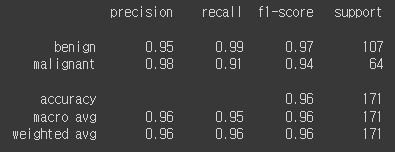
각각의 지표를 살펴보면 양성인경우는 98%의 정확도로 높게 나오고 있다.
lr_metrics = calculate_metrics(y_test, y_pred, lr_duration, 'logistic_regression')
lr_metrics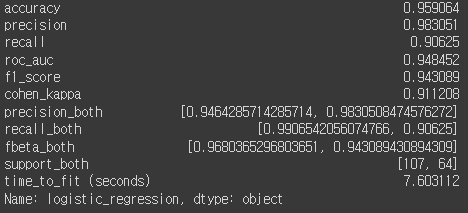
나중에 한눈에 보기위해서 평가지표도 따로 추출해두었다.
(3) K-Nearest Neighbors
주로 작은 데이터셋에 사용한다.
from sklearn.neighbors import KNeighborsClassifier
param_grid = {'weights': ['uniform', 'distance'],
'n_neighbors': np.arange(1,16)}
knn_clf = KNeighborsClassifier()
gs_knn = GridSearchCV(knn_clf, param_grid=param_grid)
start = time()
gs_knn.fit(X_train_std, y_train)
knn_duration = time() - start
print("GridSearchCV of KNN took {:.2f} seconds for {} candidate parameter settings.".format(knn_duration,
len(gs_knn.cv_results_['params'])))
# report(gs_knn.cv_results_)
print('Optimal weights: {} Optimal n_neighbors: {}'.format(gs_knn.best_params_['weights'], gs_knn.best_params_['n_neighbors']))
print('Accuracy (train): {:.2f}'.format(gs_knn.score(X_train_std, y_train)))
print('Accuracy (test): {:.2f}'.format(gs_knn.score(X_test_std, y_test)))
GridSearchCV를 사용해서 최적의 파라미터로 학습시켜준다.
pprint(gs_knn.best_estimator_.get_params())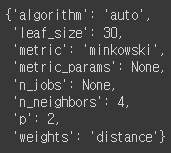
최적의 파라미터로 어떤것을 사용했는지도 확인
knn_cv = get_cross_val(gs_knn, X_test_std, y_test, 'k-nearest neighbors')
knn_cv.round(2)
로지스틱회귀보다는 평균값이 조금 떨어진다.
그래도 특정 데이터셋에는 잘 동작하는 것으로 보인다.
predictions = gs_knn.predict(X_test_std)
cm = confusion_matrix(y_test, predictions)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=gs_knn.classes_)
disp.plot()
로지스틱회귀보다 양성은 한개 덜 맞추고, 음성은 한개 더 맞춘것으로 확인된다.
y_pred = gs_knn.predict(X_test_std)
print(classification_report(y_test, y_pred,
target_names=list(np.unique(df['diagnosis']))))
그래도 로지스틱회귀와 흡사한 결과를 나타내고 있다.
knn_metrics = calculate_metrics(y_test, y_pred, knn_duration, 'k-nearest neighbors')
knn_metrics
KNN도 평가지표 추출!
(4) Linear Discriminant Analysis
LDA는 데이터 자체의 분포를 확인할때 사용하는 모델
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
param_grid = {'solver': ['lsqr', 'eigen'],
'shrinkage': [None, 'auto'],
'n_components': np.arange(1,5)} # 상한선은 feature에 루트씌운 값 정도로 사용
lda_clf = LinearDiscriminantAnalysis()
gs_lda = GridSearchCV(lda_clf, param_grid=param_grid)
start = time()
gs_lda.fit(X_train_std, y_train)
lda_duration = time() - start
print("GridSearchCV of LDA took {:.2f} seconds for {} candidate parameter settings.".format(lda_duration,
len(gs_lda.cv_results_['params'])))
# report(gs_lda.cv_results_)
print('Optimal solver: {} Optimal shrinkage: {} Optimal n_components: {}'.format(gs_lda.best_params_['solver'], gs_lda.best_params_['shrinkage'], gs_lda.best_params_['n_components']))
print('Accuracy (train): {:.2f}'.format(gs_lda.score(X_train_std, y_train)))
print('Accuracy (test): {:.2f}'.format(gs_lda.score(X_test_std, y_test)))
lda_cv = get_cross_val(lda_clf, X_test_std, y_test, 'linear discriminanat analysis')
lda_cv.round(2)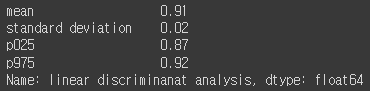
평균값이 이전 두개의 모델에 비해 떨어졌다.
그래도 표준편차는 가장 작은편
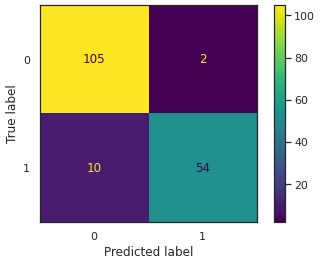
KNN에 비해서 음성을 5개나 틀려버려서 성능이 떨어진듯하다.
y_pred = gs_lda.predict(X_test_std)
print(classification_report(y_test, y_pred,
target_names=list(np.unique(df['diagnosis']))))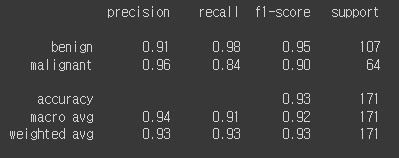
양성의 경우는 별로 떨어지지 않았지만 음성의 정확도의 경우가 많이 떨어졌다.
lda_metrics = calculate_metrics(y_test, y_pred, lda_duration, 'linear discriminant analysis')
lda_metrics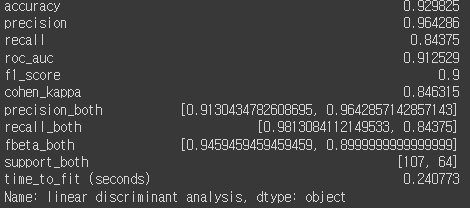
LDA도 평가지표 추출!
(5) Support Vector Machines
한때 센세이션이었다는 SVM, 요즘은 조금 철이 지났다고 한다ㅎ
from sklearn.svm import SVC
param_grid = {'C': np.power(10, np.arange(0, 3, dtype=float)),
'kernel': ['linear', 'sigmoid', 'rbf'],
'gamma': ['auto', 'scale']}
svc_clf = SVC(random_state=0)
gs_svc = GridSearchCV(svc_clf, param_grid=param_grid)
start = time()
gs_svc.fit(X_train_std, y_train)
svc_duration = time() - start
print("GridSearchCV of SVC took {:.2f} seconds for {} candidate parameter settings.".format(svc_duration,
len(gs_svc.cv_results_['params'])))
# report(gs_svc.cv_results_)
print('Optimal C: {} Optimal kernel: {} Optimal gamma: {}'.format(gs_svc.best_params_['C'], gs_svc.best_params_['kernel'], gs_svc.best_params_['gamma']))
print('Accuracy (train): {:.2f}'.format(gs_svc.score(X_train_std, y_train)))
print('Accuracy (test): {:.2f}'.format(gs_svc.score(X_test_std, y_test)))
train 정확도가 100%.. 100%의 경우는 의심을 하게 된다..
SVM답게 속도는 빠른편
svc_cv = get_cross_val(gs_svc, X_test_std, y_test, 'support vector machines')
svc_cv.round(2)
정확도는 오늘 사용한 모델중에 가장 낮은 편
predictions = gs_svc.predict(X_test_std)
cm = confusion_matrix(y_test, predictions)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=gs_svc.classes_)
disp.plot()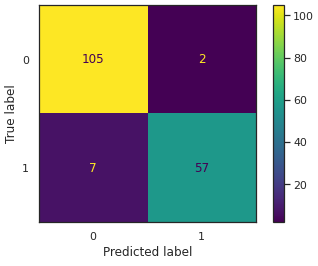
확인해보니 LDA보다는 틀린게 적었다.
y_pred = gs_svc.predict(X_test_std)
print(classification_report(y_test, y_pred,
target_names=list(np.unique(df['diagnosis']))))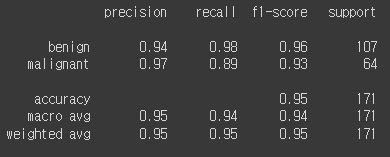
svc_metrics = calculate_metrics(y_test, y_pred, svc_duration, 'support vector machines')
svc_metrics
평가지표까지 추출!
(6) Random Forest
from sklearn.ensemble import RandomForestClassifier
param_grid = {'n_estimators': np.arange(100, 1000, 200, dtype=int),
'max_features': [None, 'sqrt', 'log2'],
'criterion': ['gini', 'entropy'],
'max_depth': [None, 3, 5, 7]}
rf_clf = RandomForestClassifier(oob_score=True, random_state=0)
gs_rf = GridSearchCV(rf_clf, param_grid=param_grid)
start = time()
gs_rf.fit(X_train_std, y_train)
rf_duration = time() - start
print("GridSearchCV of RF took {:.2f} seconds for {} candidate parameter settings.".format(rf_duration,
len(gs_rf.cv_results_['params'])))
# report(gs_rf.cv_results_)
print('Optimal n_estimators: {} Optimal max_features: {} Optimal max_depth: {} Optimal criterion: {}'.format(gs_rf.best_params_['n_estimators'],
gs_rf.best_params_['max_features'],
gs_rf.best_params_['max_depth'],
gs_rf.best_params_['criterion']))
print('Accuracy (train): {:.2f}'.format(gs_rf.score(X_train_std, y_train)))
print('Accuracy (test): {:.2f}'.format(gs_rf.score(X_test_std, y_test)))
트리류 모델은 오버피팅의 가능성이 높아 max_depth를 꼭 넣어주는것이 좋다.
약 20분정도의 시간이 소요,,
clf_rf = RandomForestClassifier(n_estimators=gs_rf.best_params_['n_estimators'],
max_features=gs_rf.best_params_['max_features'],
max_depth=gs_rf.best_params_['max_depth'],
criterion=gs_rf.best_params_['criterion'],
oob_score=True,
random_state=0)
rf_cv = get_cross_val(clf_rf, X_test_std, y_test, 'random forest')
rf_cv.round(2)
정확도는 사용모델중 높은편은 아니나 특정 데이터셋에 한해서는 제일 높게 나왔다.
predictions = gs_rf.predict(X_test_std)
cm = confusion_matrix(y_test, predictions)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=gs_rf.classes_)
disp.plot()
y_pred = gs_rf.predict(X_test_std)
print(classification_report(y_test, y_pred,
target_names=list(np.unique(df['diagnosis']))))
rf_metrics = calculate_metrics(y_test, y_pred, rf_duration, 'random forest')
rf_metrics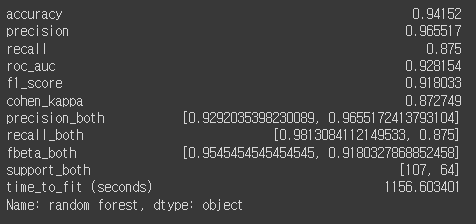
from sklearn.inspection import permutation_importance
result = permutation_importance(gs_rf, X_test_std, y_test, n_repeats=10,
random_state=42, n_jobs=-1)
sorted_idx = result.importances_mean.argsort()
X_test_df = pd.DataFrame(X_test_std, columns=list(df.iloc[:, 2:].columns))
f, ax = plt.subplots(figsize=(8,16))
ax.boxplot(result.importances[sorted_idx].T,
vert=False, labels=X_test_df.columns[sorted_idx])
ax.set_title("Permutation Importances (test set)")
plt.tight_layout();
또한 트리모델에서의 장점중 하나인 importance를 그래프로 나타낼 수 있다는점
각각의 feature들이 얼마나 영향을 끼쳤는지 그래프로 확인이 가능하다.
3. 종합
model_metrics = pd.concat([lr_metrics, knn_metrics, lda_metrics, svc_metrics, rf_metrics], axis=1).T
model_metrics.apply(lambda elem: [np.round(val, 2) for val in elem]).sort_values(by='f1_score', ascending=False)
한눈에 보기 위해서 각각의 평가지표를 합쳐서 f1 score가 가장 높은 순서대로 정렬해주었다.
target값이 binary라 그런가? 로지스틱회귀가 가장 높았다. 하지만 학습시간은 조금 있는편.
그리고 Random Forest 모델의 경우 약 500개의 데이터를 학습하는데도 20분이 걸려서 사용하기에는 어려운 모델로 판단된다.
각각의 환경에 맞게 모델을 선택할 수 있다.
cross_vals = pd.concat([lr_cv, knn_cv, lda_cv, svc_cv, rf_cv], axis=1).T
cross_vals = cross_vals.round(2).sort_values(by='mean', ascending=False)
cross_vals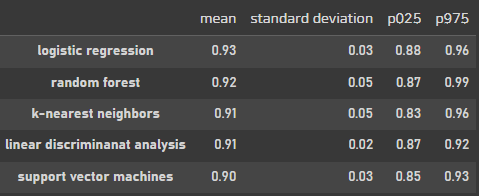
모델을 학습할때 폴드를 똑같이 5개로 나눴었는데, 폴드를 나눴을때 편차가 어느정도 나오는지도 확인해 보았다.
편차가 가장적은건 LDA모델로 판별.
fig = plt.figure(figsize=(8,6))
for i in range(len(cross_vals.index)):
plt.errorbar(x=i, y=cross_vals.iloc[i, 0], # mean column
xerr=0.25,
yerr=cross_vals.iloc[i, 1], # standard deviation column alternatively: [mean - p025, p975 - mean],
linestyle='',
label=list(cross_vals.index)[i])
plt.ylim(0.7,1)
plt.title('Mean F1 Score (+/- 1 std) by Model,\nbased on 5-fold cross-validation on the test set')
plt.xlabel('Model')
plt.ylabel('F1 Score')
plt.legend(loc='lower left')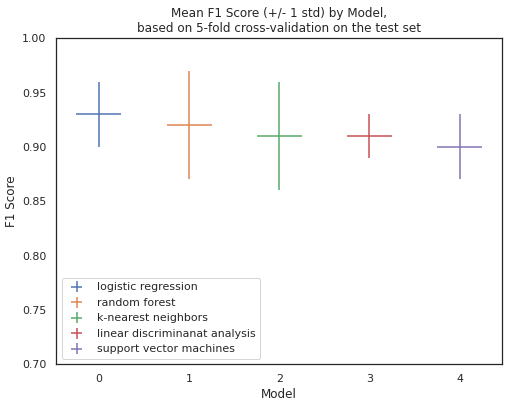
각 모델의 min, max, mean값을 확인하여 봤을때, 최고 성능을 보인건 Random Forest이지만 최저점도 그만큼 낮아 평균이 떨어지는것을 확인 할 수 있다. 편차도 적고 평균 성능도 가장 높게 나온 Logistic Regression이 오늘 사용한 데이터에는 가장 좋은 모델로 생각된다.
'개발새발 > 데이터분석' 카테고리의 다른 글
| [Python] E-commerce 행동 데이터 분석(RFM기반, Kmeans) (1) | 2024.01.31 |
|---|---|
| [Python] 어떤 동물이 빨리 입양될까?(Logistic Regression, scikit-learn, tensorflow) (3) | 2024.01.29 |
| [Python] 공기질 데이터 분석(다양한 Regression) (0) | 2024.01.19 |
| [Python] 자녀와 엄마의 IQ 상관관계 분석(OLS Regression, K-fold cross validation) (0) | 2024.01.18 |
| [Python] youtube API를 활용한 동영상 및 채널 분석 (1) | 2024.01.15 |