부트캠프때 했던 데이터분석에서 youtube API를 활용했던 적이 있는데
잊지않게 적어둡니다:D
1. Key 발급
https://console.cloud.google.com/projectselector2/apis/dashboard
Google 클라우드 플랫폼
로그인 Google 클라우드 플랫폼으로 이동
accounts.google.com
유튜브 API를 사용하기 위해서는 개인 키를 발급받아야합니다!

먼저, 클라우드 플랫폼에 들어가서 새프로젝트 생성!

이름을 적당히 넣어주고 만들기를 눌러줍니다.
검색창에 'YouTube Data API v3' 넣고 검색!

사용하기 버튼을 눌러줍니다.

순서대로 사용자 인증정보 > 사용자 인증 정보 만들기 > API키 를 눌러줍니다.

중간에 나와있는 키를 복사해서 사용하면 됩니다!
무단 사용을 방지하실 분들은 API키를 수정해서 사용해주세요:D
저는 간단한 프로젝트라서 그냥 사용했습니다!
2. 검색어로 동영상정보 추출
(1) 유튜브 API 연동하여 검색어로 동영상 정보 추출하기
# 유튜브 API 연동 및 푸바오 검색시 조회수 높은 순으로 이름 출력
from googleapiclient.discovery import build
DEVELOPER_KEY = YOUR_KEY
YOUTUBE_API__SERVICE_NAME = 'youtube'
YOUTUBE_API_VERSION = 'v3'
youtube = build(YOUTUBE_API__SERVICE_NAME, YOUTUBE_API_VERSION, developerKey = DEVELOPER_KEY)
search_query = '푸바오'
search_response = youtube.search().list(
q = search_query,
order = 'viewCount',
part = 'snippet',
maxResults = 50
).execute()중간에 DEVELOPER_KEY를 위에서 발급받은 youtube API키로 변경해주세요!
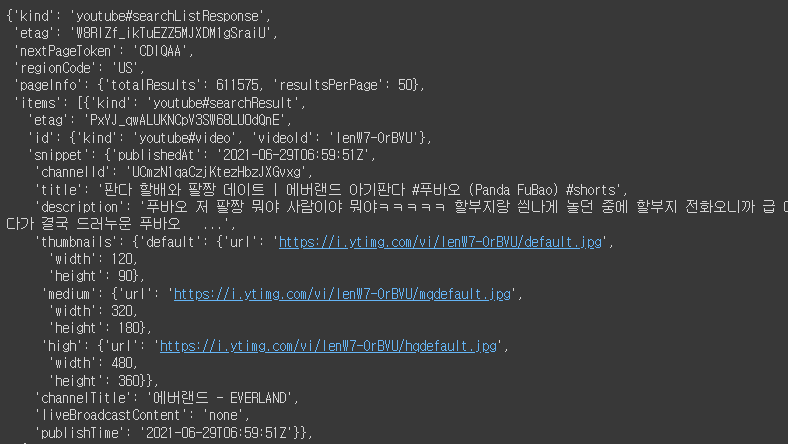
그러면 이렇게 검색어로 찾은 동영상의 정보들이 불러옵니다.
저는 조회수가 높은 순으로 50개를 뽑아봤는데 최신순, 관련도순으로도 추출이 가능합니다.
(2) 필요데이터 추출 및 가공
video_ids = [item['id']['videoId'] for item in search_response['items']]위의 데이터에서 videoId를 먼저 추출해 주었습니다.
import re
import pandas as pd
titles = [] # 동영상 제목
ids = [] # 동영상 id
dates = [] # 동영상 업로드 날짜
views = [] # 조회 수
likes = [] # 좋아요 수
#dislikes = [] # 싫어요 수는 미제공으로 주석처리
comments = [] # 댓글 수
for i in range(len(video_ids)):
request = youtube.videos().list(
id = video_ids[i], # 동영상 id를 입력합니다
part = 'snippet,contentDetails,statistics'
)
response = request.execute()
if response['items'] == []: # 동영상 정보가 없을 경우 '-'로 입력
titles.append('-')
ids.append('-')
dates.append('-')
views.append('-')
likes.append('-')
#dislikes.append('-')
comments.append('-')
else:
titles.append(response['items'][0]['snippet']['title'])
ids.append(video_ids[i])
dates.append(response['items'][0]['snippet']['publishedAt'].split('T')[0])
views.append(response['items'][0]['statistics']['viewCount'])
likes.append(response['items'][0]['statistics']['likeCount'])
#dislikes.append(response['items'][0]['statistics']['dislikeCount'])
comments.append(response['items'][0]['statistics']['commentCount'])
detail_df = pd.DataFrame([titles,dates,views,likes,comments]).T
detail_df.index = detail_df.index+1
detail_df.columns = ['title','date','view','like','comment']옛날에는 싫어요 수가 나왔었는데 요즘에는 싫어요수를 제공을 안해주더라구요!
그래서 주석처리로 남겨뒀습니다!
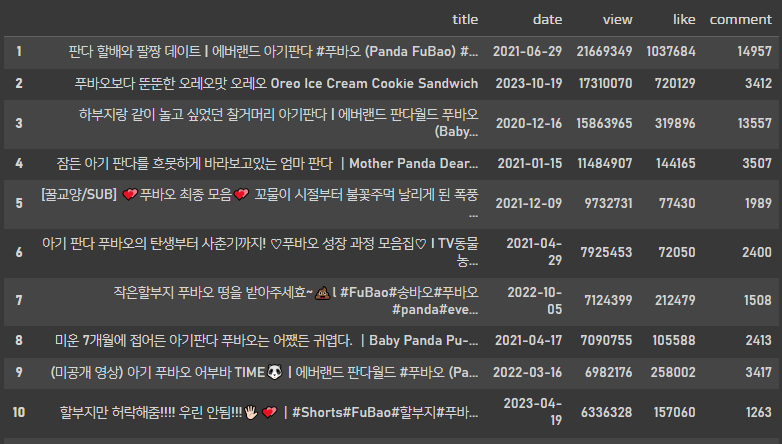
제목의 이모지까지 잘 불러오는것을 확인 할 수 있고 조회수, 좋아요수, 댓글 수 등
원하는 정보를 불러와 분석에 사용할 수 있습니다.
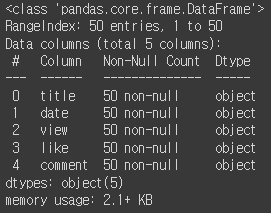
데이터 info를 보니 모두 object형태로 저장된것을 확인할 수 있습니다!
detail_df['view'] = detail_df['view'].astype(int)조회수는 추후에 사용하기 위해서 int형으로 변환해 주었습니다.
(3) matplotlib으로 그래프 출력
import pandas as pd
import matplotlib.pyplot as plt
# 푸바오 데이터
top_10_fubao = youtube_fubao.head(10)
top_10_fubao['view'] = top_10_fubao['view'].str.replace(',', '').astype(int)
top_10_fubao['순위'] = range(1, 11)
# 호랑이 데이터
top_10_tiger = youtube_tiger.head(10)
top_10_tiger['view'] = top_10_tiger['view'].str.replace(',', '').astype(int)
top_10_tiger['순위'] = range(1, 11)
# 그래프 그리기
plt.figure(figsize=(12, 6))
plt.bar(top_10_fubao['순위'] - 0.2, top_10_fubao['view'], width=0.4, color='blue', label='Fubao')
plt.bar(top_10_tiger['순위'] + 0.2, top_10_tiger['view'], width=0.4, color='red', label='Tiger')
plt.xticks(top_10_fubao['순위']) # x 축 라벨을 순위로 설정
plt.xlabel('순위')
plt.ylabel('View Count')
plt.title('Top 10 Videos by View Count (Fubao vs. Tiger)')
plt.legend()
plt.show()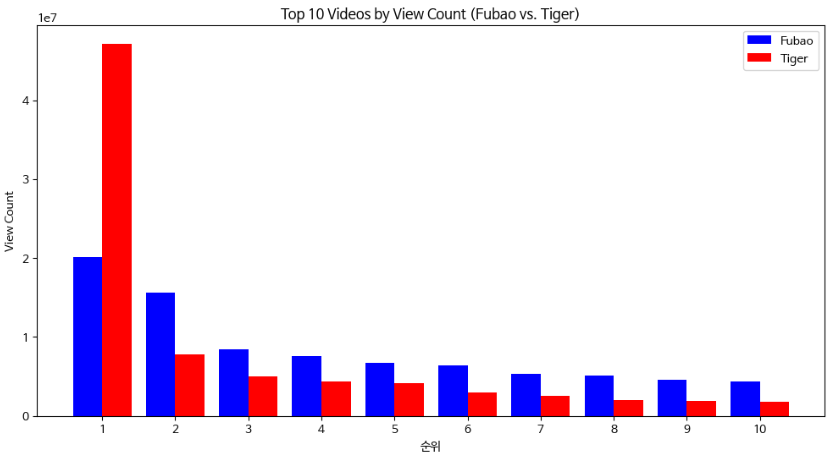
푸바오의 인기척도를 알아보기 위한 프로젝트 였기 때문에,
푸바오의 조회수 척도만 뽑기에는 비교대상이 없어서, 에버랜드 동물중 유명했던 쌍둥이 호랑이인 '태범이 무궁이'에 대한
조회수를 추가로 뽑아서 비교를 진행하였습니다.
'태범이 무궁이'는 2020.06.07에 업로드된 동영상이 조회수가 가장 많았고
'푸바오'는 2021.06.29에 업로드된 동영상의 조회수가 가장 많았습니다.
특이한 점은 1위의 태범이 무궁이의 조회수가 압도적으로 높았으나
2위부터는 모두 푸바오의 조회수가 더 높았다는 점이었습니다.
동영상이 업로드된 시점이 약 1년가량의 차이가 있던점으로 보아, 시간이 지날수록 '푸바오'의 인기가 더 높아질 것으로 예상됩니다.
3. 채널명으로 동영상 추출
from googleapiclient.discovery import build
import pandas as pd
# 유튜브 API 연동 및 '말하는동물원 뿌빠TV' 검색
DEVELOPER_KEY = YOUR_KEY
YOUTUBE_API__SERVICE_NAME = 'youtube'
YOUTUBE_API_VERSION = 'v3'
youtube = build(YOUTUBE_API__SERVICE_NAME, YOUTUBE_API_VERSION, developerKey = DEVELOPER_KEY)
search_query = '말하는동물원 뿌빠TV'
zoo_channel = youtube.search().list(
q = search_query,
order = 'relevance', # 정확도순
part = 'snippet',
maxResults = 50
).execute()
# 채널 ID 추출
channel_id = zoo_channel['items'][0]['id']['channelId']
# 채널의 동영상 목록을 가져오기
request = youtube.search().list(
part="snippet",
channelId=channel_id,
order="date", # 최신순으로 정렬
maxResults=50,
)
response = request.execute()
video_title_zoo = []
video_id_zoo = []
for item in response["items"]:
video_title = item["snippet"]["title"]
video_id = item["id"]["videoId"]
video_title_zoo.append(video_title)
video_id_zoo.append(video_id)
df = pd.DataFrame({"Video Title": video_title_zoo, "Video ID": video_id_zoo})
df.index = df.index + 1
# 말하는동물원 뿌빠TV 동영상의 상세 정보 추출
titles = [] # 동영상 제목
ids = [] # 동영상 id
dates = [] # 동영상 업로드 날짜
views = [] # 조회 수
likes = [] # 좋아요 수
comments = [] # 댓글 수
for i in range(len(video_id_zoo)):
request = youtube.videos().list(
id = video_id_zoo[i], # 동영상 id를 입력합니다
part = 'snippet,contentDetails,statistics'
)
response = request.execute()
if response['items'] == []: # 동영상 정보가 없을 경우 '-'로 입력
titles.append('-')
ids.append('-')
dates.append('-')
views.append('-')
likes.append('-')
comments.append('-')
else:
titles.append(response['items'][0]['snippet']['title'])
ids.append(video_id_zoo[i])
dates.append(response['items'][0]['snippet']['publishedAt'].split('T')[0])
views.append(response['items'][0]['statistics']['viewCount'])
likes.append(response['items'][0]['statistics']['likeCount'])
comments.append(response['items'][0]['statistics']['commentCount'])
detail_df_zoo = pd.DataFrame([titles,dates,views,likes,comments]).T
detail_df_zoo.index = detail_df_zoo.index+1
detail_df_zoo.columns = ['title','date','view','like','comment']
# 출력
print(detail_df_zoo)위의 검색어로 동영상 정보를 추출하는것과 거의 흡사합니다.
중간에 videoId 추출 부분을 channelId로만 바꿔주면 끝납니다.
정확한 채널을 찾기 위해서 동영상정보를 추출할때에 검색어와 다르게 정확도순으로 추출하였습니다.

'말하는 뿌빠 TV'의 최신 정보부터 차례대로 dataframe에 저장해줬습니다.
keywords = ['바오', '판다', '푸']
count_combined = len(detail_df_zoo[detail_df_zoo['title'].str.contains('|'.join(keywords))])
print("바오가 포함된 행의 개수:", count_combined)
print()여기서 제목에 푸, 바오, 판다 등이 들어가면 판다관련 영상으로 취급하고
에버랜드에서의 판다의 인기와 그에 따른 영상의 비율을 추출해보았습니다.
# 판다 영상의 동영상 조회수 비교
import matplotlib.pyplot as plt
import pandas as pd
detail_df_zoo['view'] = detail_df_zoo['view'].astype(int)
keywords = ['바오', '판다', '푸']
bao_views = detail_df_zoo[detail_df_zoo['title'].str.contains('|'.join(keywords))]['view'].sum()
not_bao_views = detail_df_zoo[~detail_df_zoo['title'].str.contains('|'.join(keywords))]['view'].sum()
data = [bao_views, not_bao_views]
labels = ['fubao', 'not fubao']
colors = ['#ff9999','#66b3ff']
explode = (0.1, 0)
# 도넛 차트 그리기
fig1, ax1 = plt.subplots()
ax1.pie(data, explode=explode, labels=labels, colors=colors, autopct='%1.1f%%', startangle=90)
ax1.axis('equal')
plt.title('bao view comparison')
plt.show()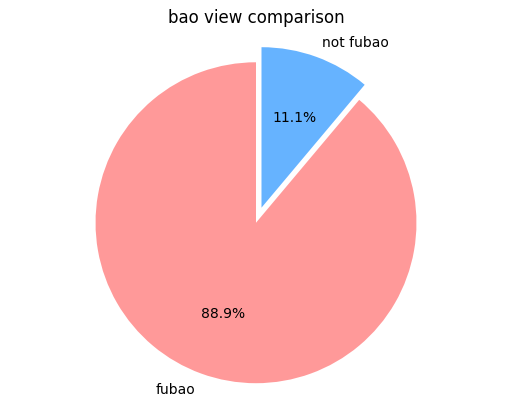
바오, 판다, 푸가 들어간 동영상의 조회수는 전체의 약 90%에 육박할정도로 인기가 많았습니다.
import matplotlib.pyplot as plt
import pandas as pd
keywords = ['바오', '판다', '푸']
contains_bao = len(detail_df_zoo[detail_df_zoo['title'].str.contains('|'.join(keywords))])
not_contains_bao = len(detail_df_zoo) - contains_bao
data = [contains_bao, not_contains_bao]
labels = ['fubao', 'not fubao']
colors = ['#ff9999','#66b3ff']
explode = (0.1, 0) # 도넛 차트처럼 구멍을 뚫기 위해 explode 값을 설정합니다.
# 도넛 차트 그리기
fig1, ax1 = plt.subplots()
ax1.pie(data, explode=explode, labels=labels, colors=colors, autopct='%1.1f%%', startangle=90)
ax1.axis('equal')
plt.title('bao contain ratio')
plt.show()
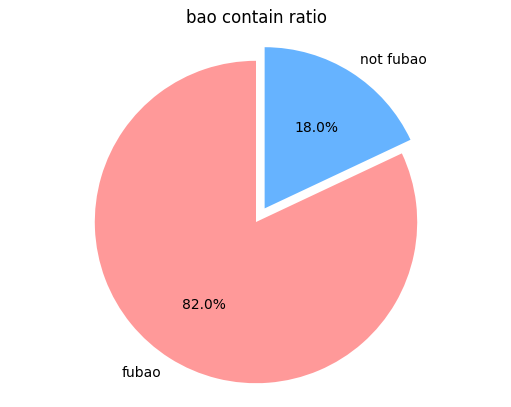
조회수가 잘나오는 판다관련 영상의 비율이 최근 50개 영상중 80%가 넘는 비율을 차지하고 있었습니다.
이때는 프로젝트 기간에 맞추기 급급해서 유튜브 동영상 분석은 이정도로 끝내었으나 글을 쓰다보니
조회수가 잘 나올수록 영상의 비율이 높아지고, 영상의 비율이 높아질수록 조회수도 높아지는거 아닐까 라는 생각을 해보았습니다.
조회수와 비율의 상관관계는 더 분석하여 이 글에 추가해보도록 하겠습니다:D

부트캠프를 하면서 총 3번의 프로젝트가 있었는데
이때가 가장 재미있고 또 다양한 데이터를 사용했던 프로젝트 였던것같습니다.
저를 알아보는 사람이있다면 댓글로 당근을 흔들어주세요~
'개발새발 > 데이터분석' 카테고리의 다른 글
| [Python] 유방암 환자 분류 모델(Logistic Regression, KNN, LDA, SVM, Random Forest) (1) | 2024.01.27 |
|---|---|
| [Python] 공기질 데이터 분석(다양한 Regression) (0) | 2024.01.19 |
| [Python] 자녀와 엄마의 IQ 상관관계 분석(OLS Regression, K-fold cross validation) (0) | 2024.01.18 |
| [Python] 당뇨환자 재입원 예측모델(one-hot encoding, optuna, shap) (2) | 2024.01.14 |
| [Python] 의류판매량예측(시계열,RandomForest) (2) | 2024.01.13 |