데이터 출처 : https://archive.ics.uci.edu/ml/datasets/online+retail
UCI Machine Learning Repository
This dataset is licensed under a Creative Commons Attribution 4.0 International (CC BY 4.0) license. This allows for the sharing and adaptation of the datasets for any purpose, provided that the appropriate credit is given.
archive.ics.uci.edu
UCI에서 받은 E-commerce 구매 데이터를 이용하여 행동 데이터 분석을 진행해 보았습니다.
여기서 오늘 할 RFM기반 분석이란?
- CRM(Customer relationship management)에서 많이 활용되는 고객 가치 분석 방법론
- RFM은 Recency, Frequency, Monetary의 약자
○ Recency : 고객이 얼마나 최근에 구매하였는가?, 얼마나 최근에 우리가 원하는 행동을 했는지를 의미한다.
○ Frequency : 고객이 얼마나 자주 방문했는가?, 우리가 원하는 특정 행동을 얼마나 자주 했는지를 의미한다. 행동 빈도.
○ Monetary : 고객이 돈을 많이 쓰는가?, 우리가 원하는 특정 행동에서 많은 양적 구매를 많이 하는지를 의미한다.
고객의 행동패턴을 분석하여 VIP고객 등 고객을 분류해보자.
1,. 데이터 로드 및 EDA
(1) 라이브러리 import
# library for feature engineering and EDA
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from IPython.display import Image
from datetime import datetime
import random
# library for statistic
from scipy import stats
from scipy.stats import skew
from scipy.stats import kurtosis
# library for machine learning
import sklearn
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
from sklearn.cluster import KMeans
%matplotlib inline(2) 데이터 로드 후 확인
df.head()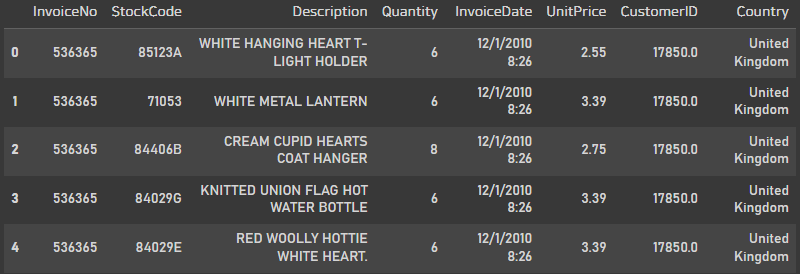
고객이 어떤물건을 얼만큼, 언제구매했는지 그 물건의 가격이 얼마인지, 어디서 주문했는지 등의 정보를 얻을 수 있다.
(3) 데이터 전처리
print("중복된 항목 수 :", len(df[df.duplicated()]))>> 중복된 항목 수 : 5268
중복된 항목 수를 먼저 살펴보면 약 5000개로 적지 않은 수 이다.
분석에 정확성을 위해 삭제를 해준다. 중복된 항복의 수가 꽤 많은거 보니 데이터를 저장할 때에 무슨 문제가 있나? 등의
생각을 해볼 수 있을것같다.
df = df.drop_duplicates().reset_index(drop=True)중복된 항목 삭제.
(4) EDA
df.info()
다양한 타입의 column들이 있다. 날짜가 그냥 object타입으로 설정되어있어 후에 datatime형태로 바꿔주겠다.
for column_name in list(df.columns):
print(column_name, df[column_name].dtype, df[column_name].unique())
카테고리, 숫자형 컬럼들의 데이터를 살펴보았다.
데이터분석에서 가장 중요한것은 눈으로 계속 확인하는것이라고 생각한다.
list_cast_to_object = ["CustomerID"]
for column_name in list_cast_to_object:
df[column_name] = df[column_name].astype(object)
list_categorical_columns = list(df.select_dtypes(include=['object']).columns)
list_numeric_columns = list(df.select_dtypes(include=['float64','int64']).columns)
print(len(df))
print(len(df.columns))
print(len(list_categorical_columns))
print(len(list_numeric_columns))
고객ID의 경우 고객을 나타내는 지표이기 때문에 숫자형 -> 문자형으로 변환해주었다.
list_numeric_columns>> ['Quantity', 'UnitPrice']
숫자형 컬럼들도 확인
df.isna().sum()
결측값을 확인해보았을때 Description과 CustomerID만 있는것을 확인하였다.
df[list_categorical_columns].nunique().sort_values()
불필요한 컬럼이 있을까 하고 확인해보았는데, 여기서는 특별히 보이지 않는 것 같다.
df = df.drop(["Description"], axis=1)
list_categorical_columns.remove("Description")Description은 상품설명으로 NLP모델이 따로 필요하기 때문에 고객 행동분석에는 맞지 않는 데이터라 판단하고 제거해 주었다.
list_categorical_columns>> ['InvoiceNo', 'StockCode', 'InvoiceDate', 'CustomerID', 'Country']
Description 컬럼 삭제되고, CustomerID도 카테고리컬럼으로 잘 바뀐것을 확인 했다.
(4)-1. 컬럼별 분포 확인
- InvoiceNo별로 몇개의 distinct 상품 개수를 구매하는가?
df_invoiceno_count = df.groupby("InvoiceNo").count()["StockCode"]
sns.histplot(df_invoiceno_count)
일반 히스토그램으로 그리니 너무 촘촘해서 잘 보이지 않는다.
sns.boxplot(df_invoiceno_count)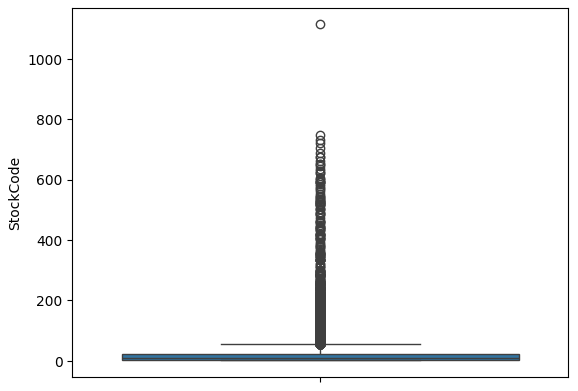
boxplot으로 변경하여 살펴보니 0~200사이가 가장 촘촘하고 딱 하나의 데이터가 1000을 넘어가는 것을 확인했다.
df_invoiceno_count.describe()
data describe로 확인해보았다.
여기서 분포가 꽤나 커서 mean값는 거의 의미가 없어보이고, max값중 하나가 1114로 중간값이 23인것을 보면 엄청 큰 숫자이다.
no_invoice_max = df_invoiceno_count[df_invoiceno_count == 1114]
print(no_invoice_max.index[0])
df[df.InvoiceNo == no_invoice_max.index[0]]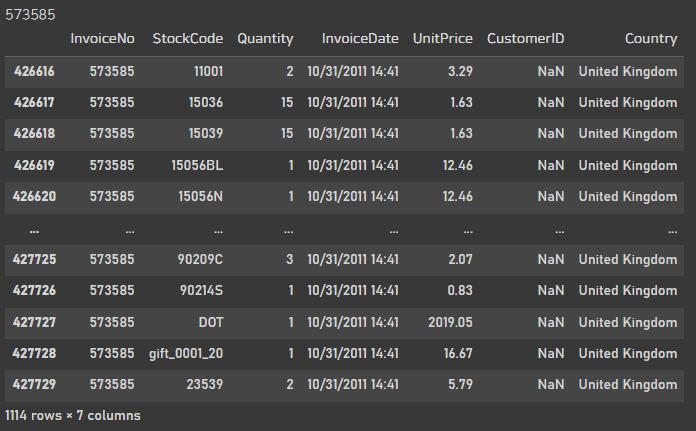
1114개를 주문한 invoice를 확인해보았다.
아마 어디 단체나 큰 기업같은곳에서 주문을 한게 아닌가? 라는 생각이 든다.
df = df.dropna().reset_index(drop=True)딱 하나 있는 데이터라 결측치로 판단하고 삭제해준다.
df_invoiceno_count = df.groupby("InvoiceNo").count()["StockCode"]
sns.boxplot(df_invoiceno_count)
확실히 아까보다 눈이 편안한 그래프가 되었다
df_invoiceno_count.describe()
max값도 542로 확 줄은 것을 확인 할 수 있다.
- 상품별로 얼마나 구매를 많이 하는가?
df.StockCode.nunique()>> 3684
no_stockcode_buy = df.groupby("StockCode").count()["InvoiceNo"]
no_stockcode_buy.sort_values(ascending=False)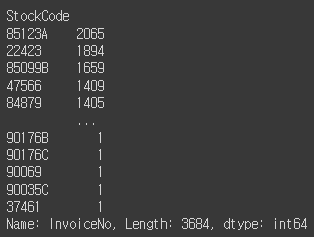
확실히 눈에 띄게 잘팔리는 베스트셀러 제품들이 있다.
no_stockcode_buy.describe()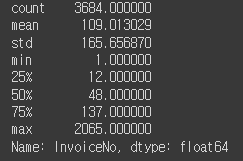
요거는 따로 결측치를 처리하지 않고 넘어간다.
- 요일에 따른 상품 구매율이 차이가 있을까?
df["InvoiceDate"] = pd.to_datetime(df.InvoiceDate)
df_tmp = df
df_tmp["weekday"] = df.InvoiceDate.dt.weekday
df_tmp["month"] = df.InvoiceDate.dt.month
df_tmp["hour"] = df.InvoiceDate.dt.hour
df_tmp.head(2)먼저 object형으로 되어있던 날짜데이터를 datatime으로 바꾸어준뒤 요일, 월, 시간으로 사용할 데이터를 나누어 주었다.
df_tmp.groupby("weekday").count()["Quantity"].plot.bar()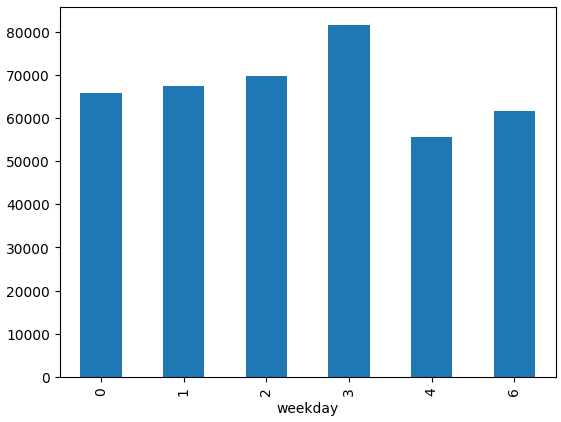
파이썬 코드상 0부터 일요일로 친다.
5번 금요일이 없는 데이터임을 확인했다.
데이터 수집시에 누락되었을 가능성이 있다고 생각한다.
대체로 주말보단 평일에 구매를 더 많이 하는데, 그중에서도 수요일이 압도적으로 높았다.
반대로 목요일엔 갑자기 뚝 떨어지는 양상을 보였다.
df_tmp.groupby("month").count()["Quantity"].plot.bar()
월별 구매량을 그래프로 찍어보았다.
연초보다는 연말, 그 중에서도 11월달이 가장 많은 판매량을 보이고 있다.
아무래도 해외 데이터이다보니 블랙프라이데이가 영향을 끼치지 않았을까? 라는 생각이 든다.
df_tmp.groupby("hour").count()["Quantity"].plot.bar()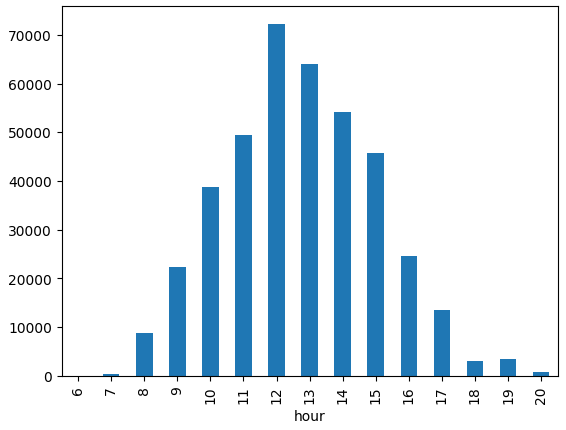
시간대 별로 확인을 해보면 정오가 가장 구매량이 많았고, 대부분 낮타임이나 회사 출근시간동안의 구매밖에 없다.
- 국가별 상품 구매율이 차이가 있을까?
df.Country.nunique()>> 37
df.groupby("Country").count()["Quantity"].plot.bar()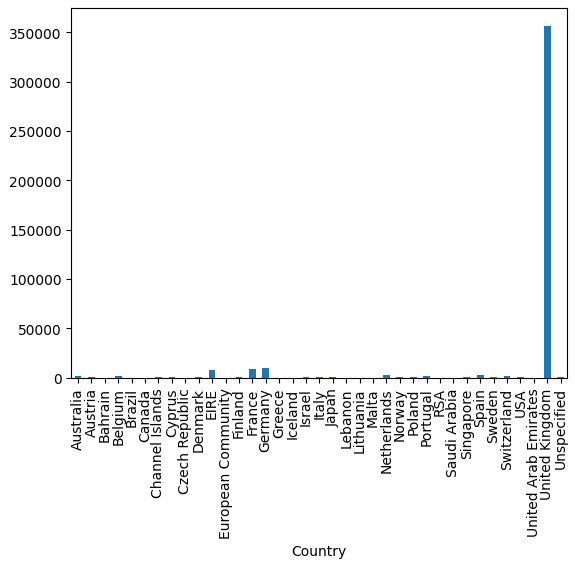
대부분이 UK 영국에서 구매되었다는것을 확인했다.
그 이외에도 유럽 국가에서 대부분 구매를 하는 듯 하다.
(4)-2. 숫자형 데이터 체크
df[list_numeric_columns].describe()
Quantity의 min 값이 마이너스로 확인되는데 한번 체크를 해봐야 겠다.
df[df.Quantity < 0 ]
아마도 -데이터는 환불데이터로 확인 된다.
df = df[df.Quantity > 0]df[list_numeric_columns].describe()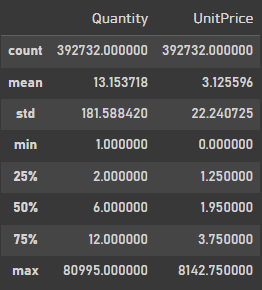
이번엔 환불데이터가 아닌 환불하지 않은 순 구매량을 가지고 분석을 해보겠다.
sns.boxplot(df["Quantity"])
그래프를 그려 확인해보니, 구매량에도 너무 큰 이상치 두개가 확인 된다.
1년에 2개의 데이터 정도라면 정확한 분석에 오류를 줄 수 있다고 판단하여 제거하기로 했다.
df = df[df.Quantity < 10000]
sns.boxplot(df["Quantity"])
10000개 이하의 데이터만 추출 했다.
sns.boxplot(df["UnitPrice"])
상품 가격도 확인.
df.isna().sum()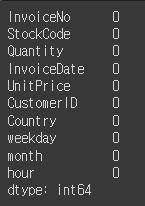
결측치를 확인했을때 깔끔히 없어졌다!
2. Feature Engineering
df_customer_last_date = df.groupby("CustomerID").agg(max)["InvoiceDate"].reset_index()
df_customer_last_date.head(2)
먼저 RFM분석을 하기 위해서 Recency Feature를 가공해보겠다.
고객 아이디를 기준으로 가장 최근 날짜를 가져왔다.
df_customer_last_date["recency"] = (df_customer_last_date["InvoiceDate"] - df["InvoiceDate"].max()).dt.days
df_recency = df_customer_last_date.drop(columns=["InvoiceDate"])
df_recency.head(3)
간단한 수식을 사용해서 플랫폼에 언제 마지막으로 접속했는지를 recency 열로 저장
df_frequency = df[["CustomerID", "InvoiceNo"]].drop_duplicates().groupby("CustomerID").count().reset_index()
df_frequency.rename(columns = {'InvoiceNo':'frequency'}, inplace = True)
df_frequency.head(3)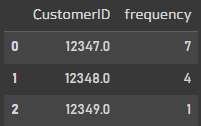
Frequency를 추출하기 위해서 고객ID별로 주문번호를 카운트 해주었다.
df["monetary_row"] = df["Quantity"] * df["UnitPrice"]
df_monetary = df.groupby("CustomerID").agg(sum)["monetary_row"].reset_index()
df_monetary.rename(columns = {'monetary_row':'monetary'}, inplace = True)
df_monetary.head(3)
Monetary를 추출하기 위해서 간단한 수식을 이용했다.
df_rfm = df_recency.merge(df_frequency, on="CustomerID").merge(df_monetary, on="CustomerID")
df_rfm.head(3)
추출한 데이터를 df로 합쳐주었다.
# RFM Score
df_rfm["recency_ntile"] = pd.qcut(df_rfm["recency"],5, labels=[1,2,3,4,5])
df_rfm["frequency_ntile"] = pd.qcut(df_rfm["frequency"].rank(method='first'), 5, labels=[1,2,3,4,5])
df_rfm["monetary_ntile"] = pd.qcut(df_rfm["monetary"],5, labels=[1,2,3,4,5])
df_rfm.head(5)RFM분석을 하기 위해 각 열의 전체 데이터를 기반으로 점수를 각각 메겨 label로 주었다.

가장 최근에, 얼마나 자주, 얼마나 많이 주문했냐에 따라 12347고객은 vip로 분류될만 하다.
(1) Scaling
MinMaxScaling을 이용하여 [0,1]로 값을 scaling 해보겠다.
# kmeans clustering 을 위한 feature
df_rfm_clustering = df_rfm.copy()
df_rfm_clustering = df_rfm_clustering[["CustomerID","recency", "frequency", "monetary"]]
df_rfm_clustering.head(2)
먼저 이후에 kmeans를 사용할 예정이기 때문에 복사해두고 데이터 더블 체크
scaler = MinMaxScaler()
list_scaling = ["recency", "frequency", "monetary"]
df_rfm_clustering.loc[:, list_scaling] = scaler.fit_transform(df_rfm_clustering[list_scaling])
df_rfm_clustering.head(2)
rfm 컬럼들이 scaling된것을 확인했다.
4. modeling
(1) heuristic RFM Analysis
df_heuristic_rfm =df_rfm.groupby(["recency_ntile","monetary_ntile","frequency_ntile"]).agg(np.mean).reset_index()
df_heuristic_rfm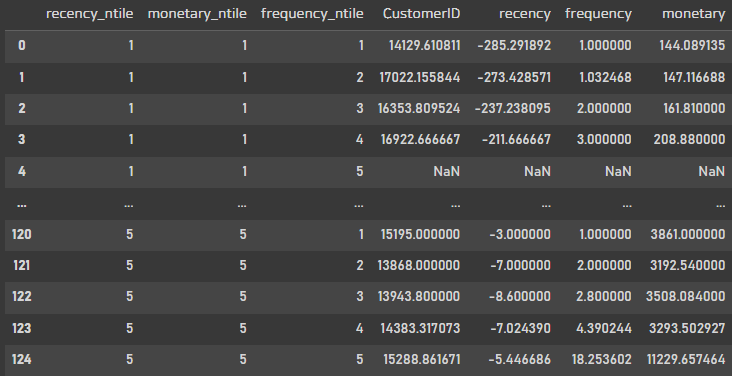
각 그룹별로 평균값을 구해보았다.
- VIP고객에게 Marketing 진행
df_rfm[(df_rfm.recency_ntile == 5) & (df_rfm.monetary_ntile == 5) & (df_rfm.frequency_ntile == 5)]
각 점수가 모두 5점인 VIP고객에게는 특별한 혜택을 준다면, 충성고객으로 만들 수 있을 것이다.
- 이전에는 구매를 많이 했지만, 최근들어 구매 이력이 없는 고객에게 마케팅
df_rfm[(df_rfm.recency_ntile == 1) & (df_rfm.monetary_ntile == 5) & (df_rfm.frequency_ntile == 5)]
떠나간지 꽤되었지만 이전엔 구매이력과 구매금액이 많았다면, 컴백이벤트 등을 만들어 혜택을 주면 다시 돌아올 가능성이 있어보이는 고객들이다.
이렇게 중간 값만 바꿔서 다양하게 CRM 마케팅을 진행할 수 있다.
(2) Kmeans
sum_of_squared_distances = []
K = range(2,20)
for k in K:
km = KMeans(n_clusters=k)
km = km.fit(df_rfm_clustering.drop("CustomerID", axis=1))
sum_of_squared_distances.append(km.inertia_)먼저 몇개의 클러스터링을 사용해야 할지 알아보기위해서 2~19개의 클러스터를 넣어서 학습을 진행해보았다.
plt.plot(K, sum_of_squared_distances, 'bx-')
plt.xlabel('k')
plt.ylabel('Sum_of_squared_distances')
plt.title('Elbow Method For Optimal k')
plt.show()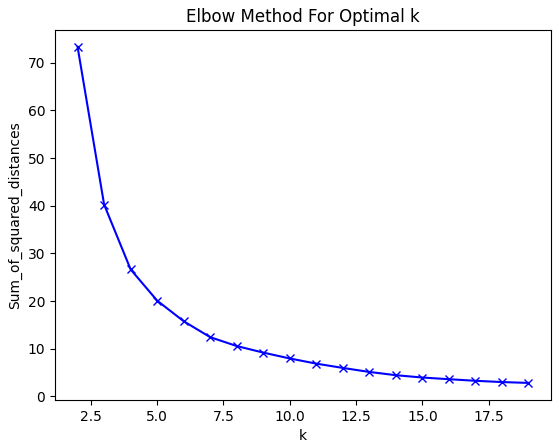
돌리면 돌릴수록 0에 가까워지겠지만, 그러면 overfitting의 가능성이 높아진다
보통 elbow point로는 곡선이 완만해지는 시점을 뽑는다.
이번에는 5를 사용하여 보겠다.
km_final = KMeans(n_clusters=5)
km_final = km_final.fit(df_rfm_clustering.drop("CustomerID", axis=1))
df_rfm_clustering["cluster_number"] = km_final.predict(df_rfm_clustering.drop("CustomerID", axis=1))
df_rfm_clustering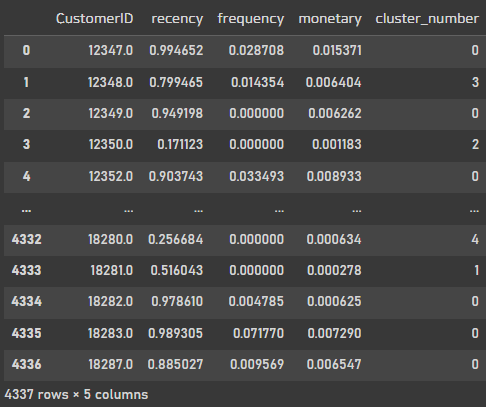
클러스터의 기준에 따라 그룹별로 묶인것을 확인
cluster_result = df_rfm_clustering.drop(columns=["CustomerID"]).groupby("cluster_number").agg(np.mean)
cluster_result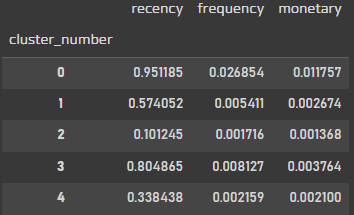
확인해보았을때, recency를 기준으로 클러스터가 된것 같다.
frequency나 moentary는 높은 값이 거의 확인 되지 않는다.
이번 데이터 분석에 사용된 데이터로 마케팅을 진행하고자한다면 clustering 분석보다는 heuristic RFM분석이 더 효과적이라고 생각된다.
'개발새발 > 데이터분석' 카테고리의 다른 글
| [Python] 공조기기 전력 사용 상태 분석(json파일 처리) (1) | 2024.02.07 |
|---|---|
| [Python] 신용카드 이상거래 탐지 모델(Undersampling, Oversampling) (2) | 2024.02.02 |
| [Python] 어떤 동물이 빨리 입양될까?(Logistic Regression, scikit-learn, tensorflow) (3) | 2024.01.29 |
| [Python] 유방암 환자 분류 모델(Logistic Regression, KNN, LDA, SVM, Random Forest) (1) | 2024.01.27 |
| [Python] 공기질 데이터 분석(다양한 Regression) (0) | 2024.01.19 |