신용카드 사용이 일반화된 요즘날
분실 및 도난시에 거래패턴이 달라지는 것을 확인하고, 카드 오용으로 인한 피해를 미연에 방지하자
1. Data load, Check
(1) 라이브러리 import
import numpy as np
import pandas as pd
import scipy.stats as stats
from time import time
from pprint import pprint
from IPython.display import Image
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style="white")
import statsmodels.api as sm
import statsmodels.formula.api as smf
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split, cross_val_score, GridSearchCV
from sklearn.metrics import classification_report, confusion_matrix, ConfusionMatrixDisplay
from sklearn.metrics import accuracy_score, precision_score, recall_score, roc_auc_score
from sklearn.metrics import f1_score, cohen_kappa_score, precision_recall_fscore_support
from sklearn.dummy import DummyClassifier
from sklearn.linear_model import LogisticRegressionCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.inspection import permutation_importance
import warnings
warnings.filterwarnings('ignore')(2) Data load

불러온 데이터는 class가 0이면 정상거래, 1이면 비정상거래로 판단하고 나머지는 신용카드 관련 정보이다.
df.columns.tolist()
이번에 사용한 데이터는 feature에 대한 Description이 없이 때문에, Feature selection을 하기가 어려운 부분이 있었다.
df.isnull().sum()
그래도 결측값은 없다.
df.groupby('class')['v1'].count()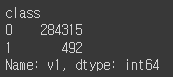
정상결제와 비정상결제건을 카운팅 해보니 데이터가 크게 불균형한것이 확인되었다.
2. Undersampling
pd.concat([df['class'].value_counts(),
df['class'].value_counts(normalize=True).round(5)], axis=1)
먼저 Undersampling 하기 전 데이터의 비율을 살펴보았다.
y0_undersampled = df.loc[df['class'] == 0, :].sample(frac=0.05, replace=False, random_state=1)
y1_undersampled = df.loc[df['class'] == 1, :].sample(frac=0.05, replace=False, random_state=1)
df_undersampled = pd.concat([y0_undersampled, y1_undersampled], axis=0)
df_undersampled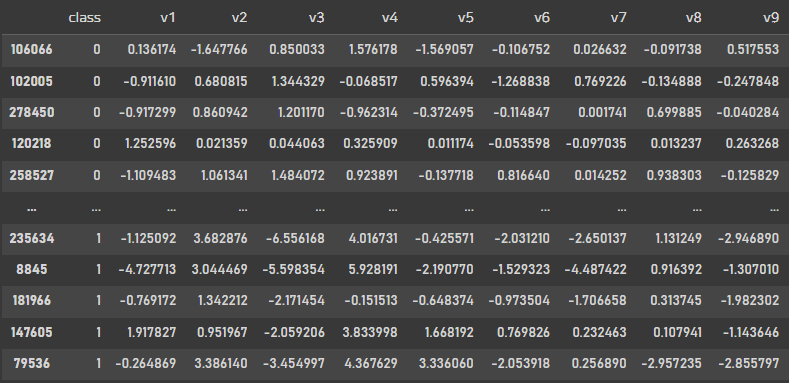
샘플을 5%의 비율로 Undersampling 해주고 데이터프레임을 생성
pd.concat([df_undersampled['class'].value_counts(),
df_undersampled['class'].value_counts(normalize=True).round(5)], axis=1)
비율은 그대로이나, 개수가 줄었다
X = df_undersampled.iloc[:, 1:].values
y = df_undersampled['class'].values.astype(int)
y_labels = ['Not Fraud', 'Fraud']
print('Class labels:', np.unique(y), y_labels, [(i, val) for (i, val) in enumerate(np.bincount(y))])
제대로 undersampling이 되었다면 x,y값으로 지정하고 확인해주었다.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.3, random_state=1, stratify=y)print('Labels counts in y:', np.bincount(y),
[round(cnt / np.sum(np.bincount(y)) * 100, 1) for cnt in np.bincount(y)])
print('Labels counts in y_train:', np.bincount(y_train),
[round(cnt / np.sum(np.bincount(y_train)) * 100, 1) for cnt in np.bincount(y_train)])
print('Labels counts in y_test:', np.bincount(y_test),
[round(cnt / np.sum(np.bincount(y_test)) * 100, 1) for cnt in np.bincount(y_test)])
전체데이터와 분할 데이터의 비율이 맞는지도 한번 더 확인 해주었다
data = pd.DataFrame(np.hstack((y_train.reshape(-1,1), X_train)),
columns=list(df.columns))
data.describe().T.round(2)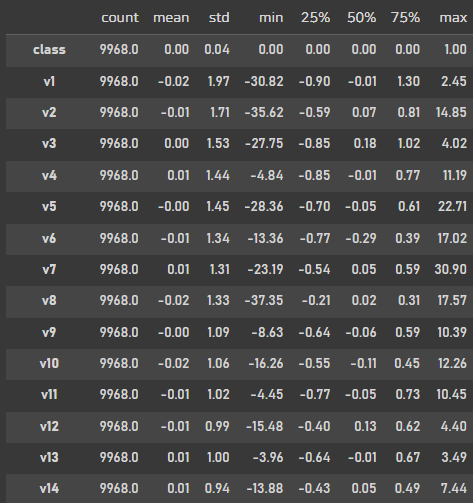
행렬변환!
f, axs = plt.subplots(15, 2, figsize=(20,70))
for i, feat in enumerate(X_train.T):
sns.distplot(feat[y_train==0], ax=axs.flat[i], label='{}: {}'.format('Not Fraud', len(y_train[y_train==0])))
sns.distplot(feat[y_train==1], ax=axs.flat[i], label='{}: {}'.format('Fraud', len(y_train[y_train==1])))
axs.flat[i].set_title('{}: mean: {} std: {}'.format(list(data.columns)[i+1], abs(feat.mean().round(2)), feat.std().round(2)))
axs.flat[i].legend()
plt.tight_layout()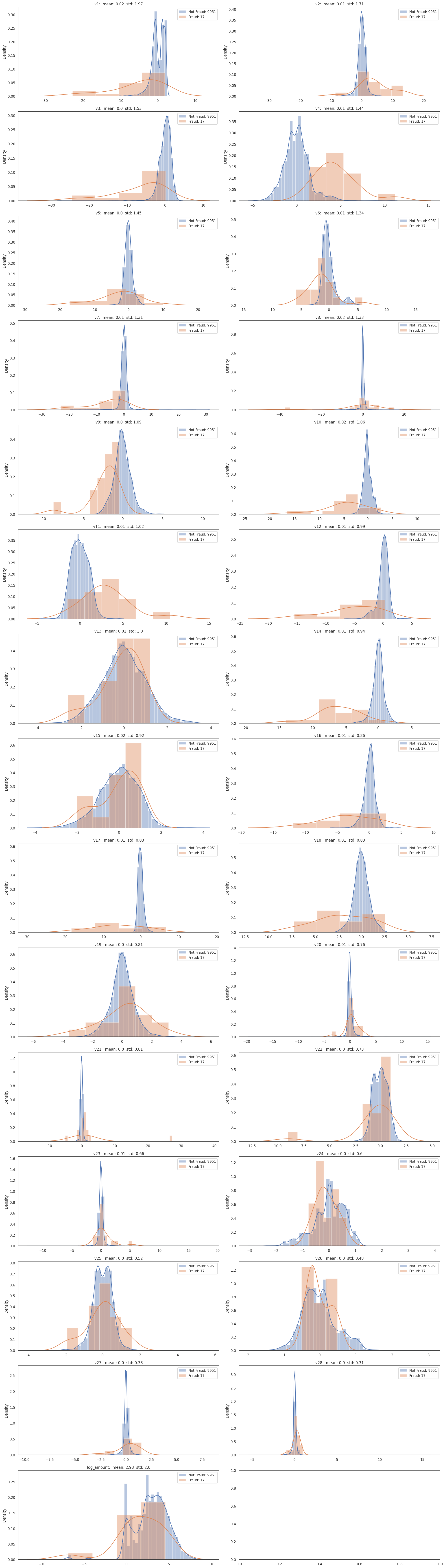
피처에 대해서 그래프를 그려보았다.
이상거래에 대한 데이터가 적다보니 좀 더 많이 퍼저있는 형태가 많이있다.
첨도를 조정한다면 사용할만한 데이터가 있어보이고, v13같은 경우에는 사용이 어려워 보이는 데이터이다.
# Feature 별 상관계수
plt.figure(figsize=(30, 30))
matrix = np.triu(data.corr())
sns.heatmap(data.corr(),
annot=True, fmt='.2g',
mask=matrix,
vmin=-1, vmax=1, center=0,
cmap=sns.diverging_palette(20, 220, n=100));
히트맵도 찍어보았는데 진한색이 안나오는거 보면, 데이터 자체가 크게 차이가 나지않고 세세하게 차이가 나는 듯 싶다.
sns.pairplot(data,
vars=list(data),
kind='reg',
diag_kind='hist',
hue='class',
# markers=['o', 's'],
corner=True,
plot_kws={'scatter_kws': {'alpha': 0.05},
'x_jitter': 0.1, 'y_jitter': 0.1});
진짜 이거 그래프 찍는데 10분이 넘게 걸렸다.ㅎ
중간중간 그래프의 선이 일치하는 데이터도 보이나 거의 대부분은 그렇지 않은편이긴 하다.
이상거래데이터가 작다보니 분포도 되게 연하게 나온다.
3. Modeling
(1) Logistic Regression
from sklearn.linear_model import LogisticRegressionCV
lr_clf = LogisticRegressionCV(cv=3,
penalty='elasticnet', solver='saga',
Cs=np.power(10, np.arange(-3, 1, dtype=float)),
l1_ratios=np.linspace(0, 1, num=6, dtype=float),
max_iter=1000,
random_state=0,
n_jobs=3)
start = time()
lr_clf.fit(X_train_std, y_train)
lr_duration = time() - start
print("LogisticRegressionCV took {:.2f} seconds for {} cv iterations with {} parameter settings.".format(lr_duration,
lr_clf.n_iter_.shape[1],
lr_clf.n_iter_.shape[2] * lr_clf.n_iter_.shape[3]))
오늘도 5개정도의 모델을 사용해 볼 예정이고 각각 모델을 비교하기 위해서 time도 같이 있어주었다.
print('Optimal regularization strength: {} Optimal L1 Ratio: {}'.format(lr_clf.C_[0], lr_clf.l1_ratio_[0]))
print('Accuracy (train): {:.4}'.format(lr_clf.score(X_train_std, y_train)))
print('Accuracy (test): {:.4f}'.format(lr_clf.score(X_test_std, y_test)))
정확도가 거의 1에 근사한 값이 나왔다.
lr_params = dict(zip(list(data.columns)[1:], list(lr_clf.coef_[0])),
intercept=lr_clf.intercept_[0])
{param: value.round(2) for (param, value) in sorted(lr_params.items(), key=lambda item: item[1], reverse=True)}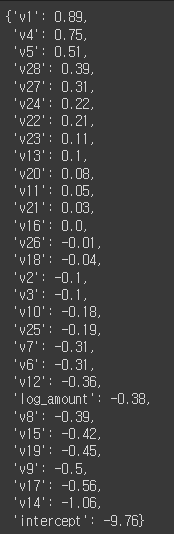
feature별 계수를 찍어보았다. v1, v14가 각각 가장 큰 영향을 미친다.
from sklearn.model_selection import cross_val_score
def get_cross_val(clf, X, y, model_name, cv_num=5, metric='f1'):
scores = cross_val_score(clf, X, y, cv=cv_num, scoring=metric)
mean = scores.mean()
std = scores.std()
p025 = np.quantile(scores, 0.025)
p975 = np.quantile(scores, 0.975)
metrics = ['mean', 'standard deviation', 'p025', 'p975']
s = pd.Series([mean, std, p025, p975], index=metrics)
s.name = model_name
return s
def calculate_metrics(y_true, y_pred, duration, model_name, *args):
acc = accuracy_score(y_true, y_pred)
pre = precision_score(y_true, y_pred)
rec = recall_score(y_true, y_pred)
roc_auc = roc_auc_score(y_true, y_pred)
f1 = f1_score(y_true, y_pred)
ck = cohen_kappa_score(y_true, y_pred)
p, r, fbeta, support = precision_recall_fscore_support(y_true, y_pred)
metrics = ['accuracy', 'precision', 'recall', 'roc_auc', 'f1_score', 'cohen_kappa',
'precision_both', 'recall_both', 'fbeta_both', 'support_both', 'time_to_fit (seconds)']
s = pd.Series([acc, pre, rec, roc_auc, f1, ck, p, r, fbeta, support, duration], index=metrics)
s.name = model_name
return s각 폴드별로도 지표를 확인하기 위해서 함수 작성
lr_cv = get_cross_val(lr_clf, X_test_std, y_test, 'logistic regression')
lr_cv.round(2)
평균값도 애매하고, 편차가 꽤 크게 나왔다.
잘 못맞춘건 5% 잘 맞춘건 79%.. 딱 봐도 편차가 크다
y_pred = lr_clf.predict(X_test_std)
cm = confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=lr_clf.classes_)
disp.plot()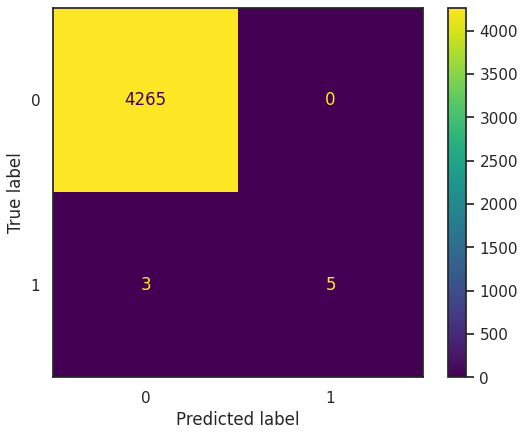
탐지 데이터 모델의 경우 오탐지보다 미탐지가 더 나쁜데 미탐지가 3개나 나와서 평균값도 낮게 나온듯 한다.
y_pred = lr_clf.predict(X_test_std)
print(classification_report(y_test, y_pred,
target_names=y_labels))
recall이 0.62로 좋지 못하다고 생각한다.
lr_metrics = calculate_metrics(y_test, y_pred, lr_duration, 'logistic_regression')
lr_metrics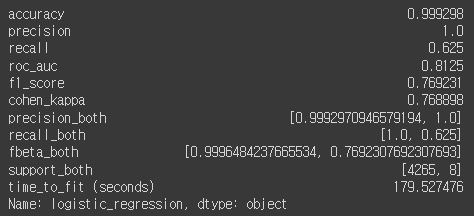
나중에 한꺼번에 보기 위해서 저장!
(2) KNN
from sklearn.neighbors import KNeighborsClassifier
param_grid = {'weights': ['uniform', 'distance'],
'n_neighbors': np.arange(1,16)}
knn_clf = KNeighborsClassifier()
gs_knn = GridSearchCV(knn_clf, param_grid=param_grid)
start = time()
gs_knn.fit(X_train_std, y_train)
knn_duration = time() - start
print("GridSearchCV of KNN took {:.2f} seconds for {} candidate parameter settings.".format(knn_duration,
len(gs_knn.cv_results_['params'])))
# report(gs_knn.cv_results_)
print('Optimal weights: {} Optimal n_neighbors: {}'.format(gs_knn.best_params_['weights'], gs_knn.best_params_['n_neighbors']))
print('Accuracy (train): {:.2f}'.format(gs_knn.score(X_train_std, y_train)))
print('Accuracy (test): {:.2f}'.format(gs_knn.score(X_test_std, y_test)))
neighbors가 7개인게 가장 좋은 모델
pprint(gs_knn.best_estimator_.get_params())
사용 파라미터도 확인해주었다.
knn_cv = get_cross_val(gs_knn, X_test_std, y_test, 'k-nearest neighbors')
knn_cv.round(2)
Logistic Regression보단 평균값이 올라갔으나, 편차는 훨씬 더 심해졌다.
y_pred = gs_knn.predict(X_test_std)
cm = confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=gs_knn.classes_)
disp.plot()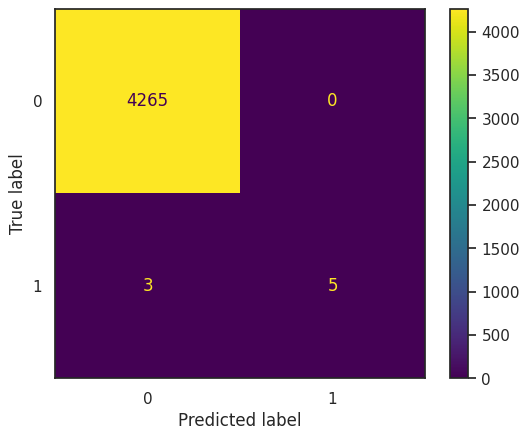
confusion matrix를 직어보니 Logistic Regression과 일치한것을 확인 할 수 있다.
y_pred = gs_knn.predict(X_test_std)
print(classification_report(y_test, y_pred,
target_names=y_labels))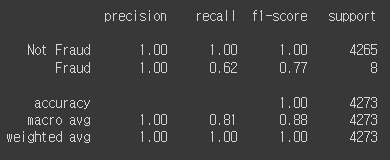
recall의 경우도 Logistic Regression과 일치
knn_metrics = calculate_metrics(y_test, y_pred, knn_duration, 'k-nearest neighbors')
knn_metrics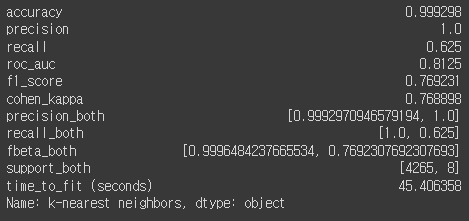
KNN도 저장!
(3) LDA
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
param_grid = {'solver': ['lsqr', 'eigen'],
'shrinkage': [None, 'auto'],
'n_components': np.arange(1,5)}
lda_clf = LinearDiscriminantAnalysis()
gs_lda = GridSearchCV(lda_clf, param_grid=param_grid)
start = time()
gs_lda.fit(X_train_std, y_train)
lda_duration = time() - start
print("GridSearchCV of LDA took {:.2f} seconds for {} candidate parameter settings.".format(lda_duration,
len(gs_lda.cv_results_['params'])))
# report(gs_lda.cv_results_)
print('Optimal solver: {} Optimal shrinkage: {} Optimal n_components: {}'.format(gs_lda.best_params_['solver'], gs_lda.best_params_['shrinkage'], gs_lda.best_params_['n_components']))
print('Accuracy (train): {:.2f}'.format(gs_lda.score(X_train_std, y_train)))
print('Accuracy (test): {:.2f}'.format(gs_lda.score(X_test_std, y_test)))
앞선 두 모델보다 시간이 확! 줄었다.
lda_cv = get_cross_val(lda_clf, X_test_std, y_test, 'linear discriminanat analysis')
lda_cv.round(2)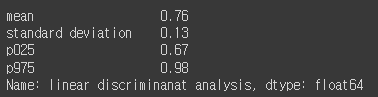
중간값이나 편차등을 확인해보아도, 앞선 두 모델보다 성능이 좋다.
y_pred = gs_lda.predict(X_test_std)
cm = confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=gs_lda.classes_)
disp.plot()
미탐지가 1개 줄었다!
y_pred = gs_lda.predict(X_test_std)
print(classification_report(y_test, y_pred,
target_names=y_labels))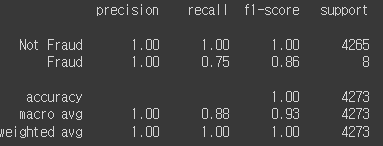
미탐지가 줄은 만큼 recall도 올라갔다!
lda_metrics = calculate_metrics(y_test, y_pred, lda_duration, 'linear discriminant analysis')
lda_metrics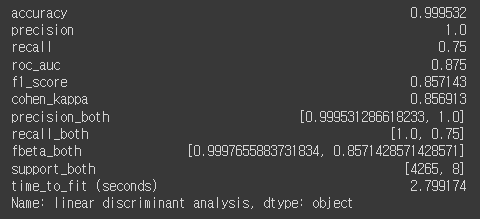
잘나온 lda도 저장!
(4) SVM
from sklearn.svm import SVC
param_grid = {'C': np.power(10, np.arange(0, 3, dtype=float)),
'kernel': ['linear', 'sigmoid', 'rbf'],
'gamma': ['auto', 'scale']}
svc_clf = SVC(random_state=0)
gs_svc = GridSearchCV(svc_clf, param_grid=param_grid)
start = time()
gs_svc.fit(X_train_std, y_train)
svc_duration = time() - start
print("GridSearchCV of SVC took {:.2f} seconds for {} candidate parameter settings.".format(svc_duration,
len(gs_svc.cv_results_['params'])))
# report(gs_svc.cv_results_)
print('Optimal C: {} Optimal kernel: {} Optimal gamma: {}'.format(gs_svc.best_params_['C'], gs_svc.best_params_['kernel'], gs_svc.best_params_['gamma']))
print('Accuracy (train): {:.2f}'.format(gs_svc.score(X_train_std, y_train)))
print('Accuracy (test): {:.2f}'.format(gs_svc.score(X_test_std, y_test)))
SVM역시 짧은 러닝타임을 가진다.
svc_cv = get_cross_val(gs_svc, X_test_std, y_test, 'support vector machines')
svc_cv.round(2)
그렇지만 오늘 사용 모델중 가장 낮은 값을 가져왔다.
중간값도 낮고, 편차도 큰편
y_pred = gs_svc.predict(X_test_std)
cm = confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=gs_svc.classes_)
disp.plot()
Logistic Regression기준으로 오탐지데이터와 미탐지데이터가 각각 하나씩 증가한것을 확인 할 수 있다.
y_pred = gs_svc.predict(X_test_std)
print(classification_report(y_test, y_pred,
target_names=y_labels))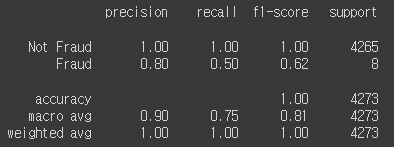
앞선 세 모델 모두 precision은 1이였는데 0.8로 줄었다. recall 또한 0.5로 감소
SVM이 가장 좋지 못한 성능이다. 이번 데이터와는 맞지 않는 모델이라고 판단한다.
svc_metrics = calculate_metrics(y_test, y_pred, svc_duration, 'support vector machines')
svc_metrics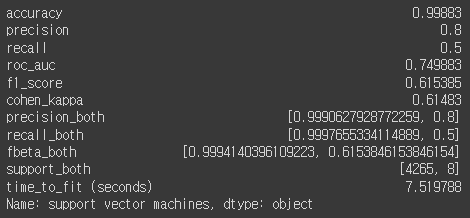
그래도 일단 저장!
(5) Random Forest
from sklearn.ensemble import RandomForestClassifier
param_grid = {'n_estimators': np.arange(100, 800, 200, dtype=int),
'max_features': [None, 'sqrt', 'log2'],
'max_depth': [None, 3, 5]}
rf_clf = RandomForestClassifier(oob_score=True, random_state=0)
gs_rf = GridSearchCV(rf_clf, param_grid=param_grid)
start = time()
gs_rf.fit(X_train_std, y_train)
rf_duration = time() - start
print("GridSearchCV of RF took {:.2f} seconds for {} candidate parameter settings.".format(rf_duration,
len(gs_rf.cv_results_['params'])))
# report(gs_rf.cv_results_)
print('Optimal n_estimators: {} Optimal max_features: {} Optimal max_depth: {}'.format(gs_rf.best_params_['n_estimators'],
gs_rf.best_params_['max_features'],
gs_rf.best_params_['max_depth']))
오늘의 하이라이트..^^
Logistic Regression이 오래걸리길래 얘도 오래걸리겠거니 했는데 중간에 한번 튕기기 까지하면서 30분이나 걸렸다.
print('Accuracy (train): {:.4f}'.format(gs_rf.score(X_train_std, y_train)))
print('Accuracy (test): {:.4f}'.format(gs_rf.score(X_test_std, y_test)))
정확도는 잘 나온다.
clf_rf = RandomForestClassifier(n_estimators=gs_rf.best_params_['n_estimators'],
max_features=gs_rf.best_params_['max_features'],
max_depth=gs_rf.best_params_['max_depth'],
oob_score=True,
random_state=0)
rf_cv = get_cross_val(clf_rf, X_test_std, y_test, 'random forest')
rf_cv.round(2)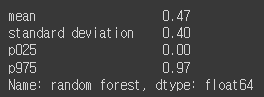
가장 나쁜 성능을 가졌다. 무려 0%인 폴드도 있다는 점.
y_pred = gs_rf.predict(X_test_std)
cm = confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=gs_rf.classes_)
disp.plot()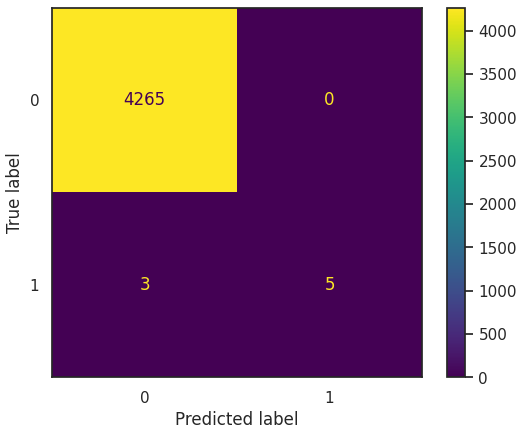
but, confusion matrix를 직었을땐 Logistic Regression, KNN과 동일한 값을 가져왔다.
y_pred = gs_rf.predict(X_test_std)
print(classification_report(y_test, y_pred,
target_names=y_labels))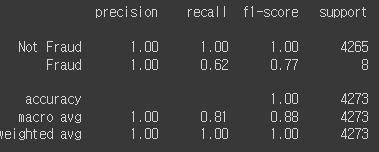
rf_metrics = calculate_metrics(y_test, y_pred, rf_duration, 'random forest')
rf_metrics
recall도 같다.
from sklearn.inspection import permutation_importance
result = permutation_importance(gs_rf, X_test_std, y_test, n_repeats=10,
random_state=42, n_jobs=-1)
sorted_idx = result.importances_mean.argsort()
X_test_df = pd.DataFrame(X_test_std, columns=list(data.columns)[1:])
f, ax = plt.subplots(figsize=(8,16))
ax.boxplot(result.importances[sorted_idx].T, # 높은 피쳐 10개만 뽑아서 해보기
vert=False, labels=X_test_df.columns[sorted_idx])
ax.set_title("Permutation Importances (test set)")
plt.tight_layout();트리류 모델에서만 찍어볼 수 있는 importance 그래프로 각각 feature의 영향을 확인해보았다.

(6) Compare
model_metrics = pd.concat([lr_metrics, knn_metrics, lda_metrics, svc_metrics, rf_metrics], axis=1).T
model_metrics.apply(lambda elem: [np.round(val, 4) for val in elem]).sort_values(by='f1_score', ascending=False)
LDA모델이 성능이 가장 좋은데, 시간도 가장 짧게 걸렸다.
cross_vals = pd.concat([lr_cv, knn_cv, lda_cv, svc_cv, rf_cv], axis=1).T
cross_vals = cross_vals.round(4).sort_values(by='mean', ascending=False)
cross_vals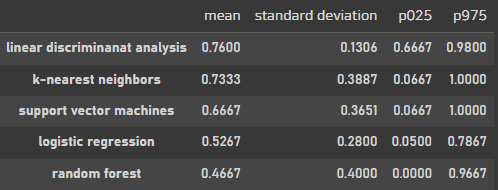
각각 폴드별로도 확인을 해봤을때 LDA가 가장 우수!
fig = plt.figure(figsize=(8,6))
for i in range(len(cross_vals.index)):
plt.errorbar(x=i, y=cross_vals.iloc[i, 0], # mean column
xerr=0.25,
yerr=cross_vals.iloc[i, 1], # standard deviation column alternatively: [mean - p025, p975 - mean],
linestyle='',
label=list(cross_vals.index)[i])
#plt.ylim(0.7,1)
plt.title('Mean F1 Score (+/- 1 std) by Model,\nbased on 5-fold cross-validation on the test set')
plt.xlabel('Model')
plt.ylabel('F1 Score')
plt.legend(loc='lower left');

두말할것도없이 이번데이터에는 LDA모델의 성능이 가장 좋았다
4. Feature Engineering
(1) Oversampling(Numpy)
bool_y_train = y_train != 0
pos_features = X_train_std[bool_y_train]
neg_features = X_train_std[~bool_y_train]
pos_labels = y_train[bool_y_train]
neg_labels = y_train[~bool_y_train]
pos_features.shape, neg_features.shape
Oversampling을 이용한 모델도 한번 시도해 보았다.
데이터의 불균형 체크해주고
ids = np.arange(len(pos_features))
choices = np.random.choice(ids, len(neg_features))
res_pos_features = pos_features[choices]
res_pos_labels = pos_labels[choices]
res_pos_features.shape, res_pos_labels.shape
resampled_features = np.concatenate([res_pos_features, neg_features], axis=0)
resampled_labels = np.concatenate([res_pos_labels, neg_labels], axis=0)
order = np.arange(len(resampled_labels))
np.random.shuffle(order)
resampled_features = resampled_features[order]
resampled_labels = resampled_labels[order]
resampled_features.shape, resampled_labels.shape
Numpy를 이용해서 Oversampling을 진행해주었다.
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
param_grid = {'solver': ['lsqr', 'eigen'],
'shrinkage': [None, 'auto'],
'n_components': np.arange(1,5)}
lda_clf = LinearDiscriminantAnalysis()
gs_lda_resamp = GridSearchCV(lda_clf, param_grid=param_grid)
start = time()
gs_lda_resamp.fit(resampled_features, resampled_labels)
lda_duration = time() - start
print("GridSearchCV of LDA took {:.2f} seconds for {} candidate parameter settings.".format(lda_duration,
len(gs_lda_resamp.cv_results_['params'])))
# report(gs_lda.cv_results_)
print('Optimal solver: {} Optimal shrinkage: {} Optimal n_components: {}'.format(gs_lda_resamp.best_params_['solver'],
gs_lda_resamp.best_params_['shrinkage'],
gs_lda_resamp.best_params_['n_components']))
print('Accuracy (train): {:.4f}'.format(gs_lda_resamp.score(resampled_features, resampled_labels)))
print('Accuracy (test): {:.4f}'.format(gs_lda_resamp.score(X_test_std, y_test)))
Undersampling 했을때 가장 좋았던 LDA모델만 가져와서 테스트 진행
Undersampling 할때는 그래도 Accuracy는 다 1이나왔는데 Oversampling을 하니 떨어졌다.
y_pred = gs_lda_resamp.predict(X_test_std)
cm = confusion_matrix(y_test, y_pred)
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=gs_lda_resamp.classes_)
disp.plot()

미탐지 데이터는 Undersampling한 Logistic Regression과 같은데, 오탐지 데이터가 확 늘어버렸다.
calculate_metrics(y_test, y_pred, knn_duration, 'oversampling numpy')
세부지표를 확인해보니 Undersampling 한 결과값에 비하면 현저히 떨어지는 모습을 모인다.
데이터 불균형시 가장 먼저 시도할 수 있는 방법은 undersampling 방법이다. oversampling은 많은 방법들이 시도 되지만, 결국 분포를 추정해야 되고 Interpolation과 같이 분포의 가운데 어딘가를 추정해야 하기 때문에 불확실성이 undersampling 방법보다는 높다.
'개발새발 > 데이터분석' 카테고리의 다른 글
| [Python] 가스 공급량 분석 및 예측 모델(시계열분석) (0) | 2024.02.13 |
|---|---|
| [Python] 공조기기 전력 사용 상태 분석(json파일 처리) (1) | 2024.02.07 |
| [Python] E-commerce 행동 데이터 분석(RFM기반, Kmeans) (1) | 2024.01.31 |
| [Python] 어떤 동물이 빨리 입양될까?(Logistic Regression, scikit-learn, tensorflow) (3) | 2024.01.29 |
| [Python] 유방암 환자 분류 모델(Logistic Regression, KNN, LDA, SVM, Random Forest) (1) | 2024.01.27 |