공장에는 다양한 설비가 있다. 설비들에 대한 예지보전은 생산성에 매우 큰 영향을 미치기 때문에, 센서 값에 따라 설비의 건강상태를 예측하는 것이 매우 중요한 일이다. 설비에서 발생하는 센서데이터들을 살펴보고, SOH(State Of Health)에 대해 예측할 수 있는 모델을 만들어보자.
1. Data load & Check
(1) 라이브러리 import
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import matplotlib.pyplot as plt
from statsmodels.stats.outliers_influence import variance_inflation_factor
from statsmodels.tools.tools import add_constant
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
# 한글 폰트를 사용하기 위해 나눔고딕 폰트 설치
!sudo apt-get install -y fonts-nanum
!sudo fc-cache -fv
!rm ~/.cache/matplotlib -rf(2) Data load, info
df.info()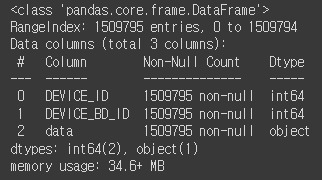
설비 번호와 설비가 설치된 건물번호, 그리고 data 컬럼이 있다.
for idx, val in enumerate(df['data'].values):
if idx == 30: break
print(val['ITEM_NAME'], val['ITEM_VALUE'], val['TIMESTAMP'])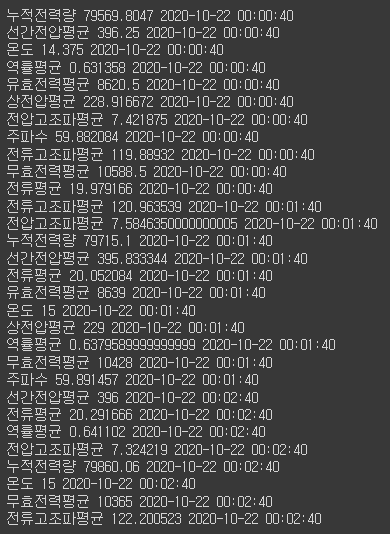
먼저 데이터를 살펴보았을 때, TIMESTAMP별로 ITEM_NAME이 동일한 것을 확인 할 수 있습니다.
df['data'][0]
object(dict) 타입으로 저장된 data column에 실제 분석 대상 데이터가 저장되어있다.
cur_date = None
for idx, val in enumerate(df['data'].values):
if idx == 30: break
print(val['ITEM_NAME'], val['ITEM_VALUE'], val['TIMESTAMP'])
if cur_date is None:
# cur_date가 비어있을 경우 TIMESTAMP로 초기화
cur_date = val['TIMESTAMP']
if cur_date == val['TIMESTAMP']:
continue
elif cur_date != val['TIMESTAMP']:
print("Detect change value of TIMESTAMP")
breakjson type으로 저장된 데이터를 분석에 사용할 수 있는 데이터로 변환해준다.
column_candidate = []
for idx, val in enumerate(df['data'].values):
column_candidate.append(val['ITEM_NAME'])
print(len(column_candidate))
set(column_candidate)
info에서 체크했듯이 1509795개가 나오고 set 자료형의 특성을 이용해서 unique한 컬럼만 남겨주었다.
TIMESTAMP별로 앞에 S상, R상, T상이 나뉘어지는 듯 합니다.
df['item_name'], df['item_value'], df['timestamp'] = zip(*df['data'].apply(lambda x: [x['ITEM_NAME'], x['ITEM_VALUE'], x['TIMESTAMP']]))
# 분석에 사용할 수 있도록 시계열 데이터로 재구성한다.
target = df.pivot(index='timestamp', columns='item_name', values='item_value').reset_index()
target위 데이터를 분석에 사용하기 위해서는 data 컬럼에 있는 dict 데이터를 풀어서 사용해야 하기 때문에
데이터를 재구성 해주었습니다.

2. Data Readiness Check
target.describe()
describe로 데이터를 살펴보았을 때, 결측값을 따로 없어보였습니다.
(1) Labeling Data load
label_df['label'], label_df['timestamp'] = zip(*label_df['data'].apply(lambda x: [x['LABEL_NAME'], x['TIMESTAMP']]))
label_df.head(5)
Feature와 Target을 합치기 위해 Labeling 된 데이터를 읽어와서 label_df에 저장한 후
LABEL_NAME과 TIMESTAMP를 이용하여 data컬럼을 읽어왔습니다.
컬럼의 제일 끝에 잘 붙어있는것을 확인!
(2) 학습데이터셋 구성
train_data = target.merge(label_df.drop_duplicates(['timestamp', 'label'])[['timestamp', 'label']], on='timestamp', how='left')
train_data.head(10)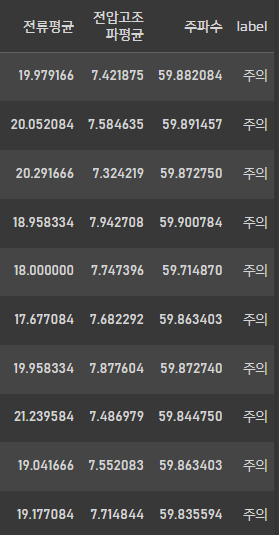
Feature와 Label을 합쳐서 학습 데이터로 구성해 주었습니다.
(3) 카테고리형으로 변경
train_data['label'].unique()
설비 상태는 주의, 정상, 경고 3가지로 나눠진다.
#0: 경고, 1:정상, 2: 주의
train_data['label'].astype('category')
astype을 이용해서 카테고리형으로 바꿔줬습니다.
train_data['label'] = train_data['label'].astype('category').cat.codes
train_data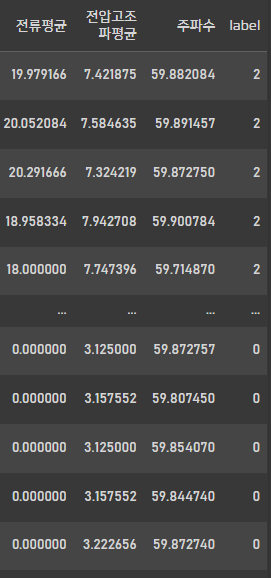
label 데이터가 숫자형으로 바뀐것을 확인 할 수 있습니다.
3. Feature Engineering
(1) histogram
plt.rc('font', family='NanumBarunGothic')
train_data.hist(figsize=(28,22))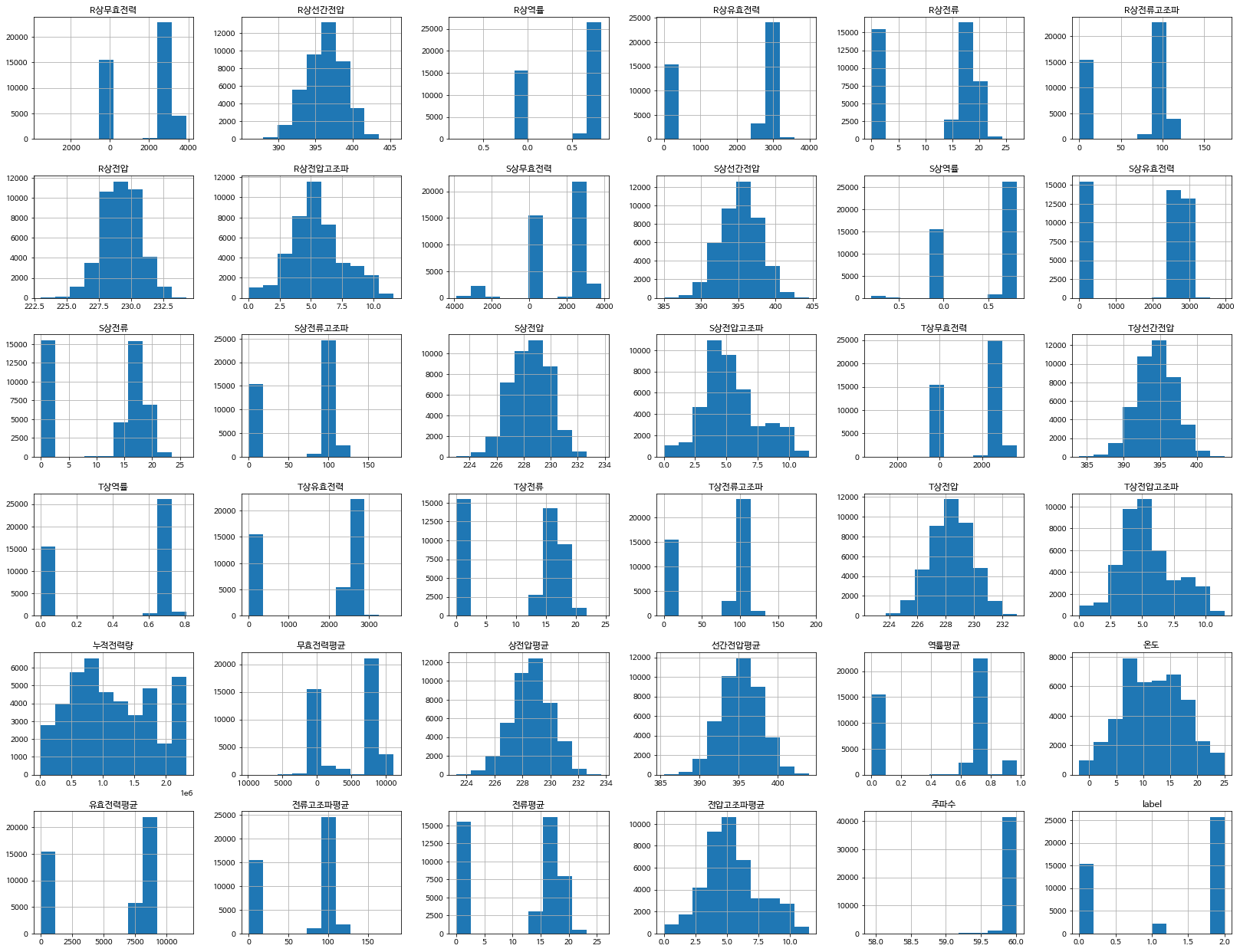
먼저 히스토그램으로 그래프를 그려보았습니다.
같은 R상, S상, T상의 그래프를 비교해보면 전반적으로 corrlation을 가지고 있는것이 눈에 띕니다.
이게 같은 모터에서 발생하는 전력이기 때문에 생기는 것이 아닐까 생각합니다.
(2) heatmap
plt.rc('font', family='NanumBarunGothic')
plt.figure(figsize=(28,12))
# Generate a mask to onlyshow the bottom triangle
mask = np.triu(np.ones_like(train_data.corr(), dtype=bool))
# generate heatmap
sns.heatmap(train_data.corr(), annot=True, mask=mask, vmin=-1, vmax=1)
plt.show()
확실히 다중공선성이 높은게 눈에 많의 띕니다!
3상 모터의 경우, R, S, T 전력, 전류가 발생하는데, 이 센서들은 서로 상관관계가 높을 수 밖에 없다고 생각합니다.
(3) VIF
# compute the vif for all given features
def compute_vif(df, considered_features):
X = df[considered_features]
X['intercept'] = 1
vif = pd.DataFrame()
vif["Variable"] = X.columns
vif["VIF"] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
vif = vif[vif['Variable']!='intercept']
return vif
# features to consider removing
considered_features = train_data.columns.tolist()
considered_features.remove('timestamp')
considered_features.remove('label')
# compute vif
compute_vif(train_data, considered_features).sort_values('VIF', ascending=False)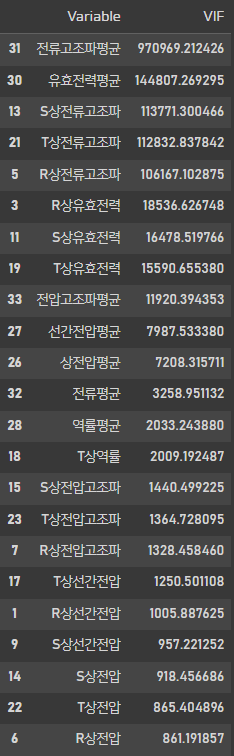

다중 공선성을 측정할 수 있는 가장 간단한 방법인 VIF를 정의했습니다.
어마어마한 값이 나옵니다.
책에서 배운대로 생각하면 VIF가 5가 넘는 Feature는 사용할 수 없다. 하지만, 이렇게 대부분의 Feature가 공선성이 높은 경우에는 모든 Feature를 이용해서 1차로 모델링을 진행하고 모델링의 결과를 이용하여 Feature Selection을 하는 방법도 있다.
4. Modeling
거의 대부분의 센서가 전력 사용에 대한 데이터기 때문에 다중공선성이 매우 높지만, 다중공선성이 높은 Feature를 제거하면 모델링할 수 있는 변수가 거의 없으므로, Feature Importance를 통해 Feature Selection을 시도하자.
(1) RandomForestClassifier
y = train_data['label']
X = train_data.drop(['label', 'timestamp'], axis=1)
train_features, test_features, train_labels, test_labels = train_test_split(X, y, test_size = 0.2, random_state = 0, shuffle=False)
rf1 = RandomForestClassifier(random_state = 0, n_estimators=50, max_features=20)
rf1.fit(train_features, train_labels)
predicted_1 = rf1.predict(test_features)
result1_train = rf1.score(train_features, train_labels)
result1_test = rf1.score(test_features, test_labels)
print(f"Train score: {result1_train}")
print(f"Test score: {result1_test}")
score가 굉장히 높게 나오는 것을 확인 할 수 있습니다.
n_estimators는 보통 100이 기본인데 데이터의 양이 많아서 50개로 줄여서 했습니다.
X = train_data.iloc[:, rf1.feature_importances_.argsort()[::-1][:10]]
y = train_data['label']
train_features, test_features, train_labels, test_labels = train_test_split(X, y, test_size = 0.2, random_state = 0, shuffle=False)Feature importance가 높은 10개를 선택하여 학습데이터를 재구성
rf2 = RandomForestClassifier(random_state = 0, n_estimators=50, max_features=20)
rf2.fit(train_features, train_labels)
predicted_2 = rf2.predict(test_features)
result2_train = rf2.score(train_features, train_labels)
result2_test = rf2.score(test_features, test_labels)
print(f"Train score: {result2_train}")
print(f"Test score: {result2_test}")
전체 데이터를 사용하나, Feature importance가 높은 10개 데이터를 선택해서 사용하나
값이 같아서 좀 더 라이트하게 사용하기 위해 10개만 가져와서 사용했습니다:D
(2) test data load
test_data
test_data['item_name'], test_data['item_value'], test_data['timestamp'] = zip(*test_data['data'].apply(lambda x: [x['ITEM_NAME'], x['ITEM_VALUE'], x['TIMESTAMP']]))
test_target = test_data.pivot(index='timestamp', columns='item_name', values='item_value').reset_index()
test_target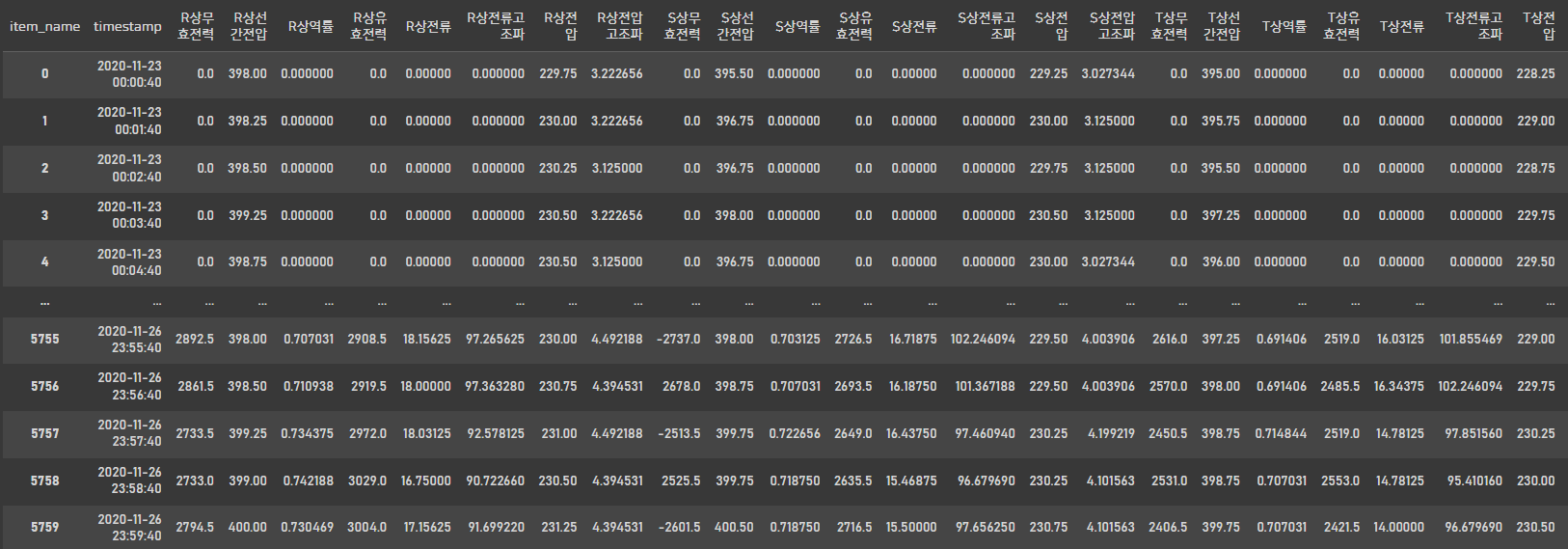
test data도 train data와 동일하게 데이터셋을 구성해주었습니다.
label_test_df['label'], label_test_df['timestamp'] = zip(*label_test_df['data'].apply(lambda x: [x['LABEL_NAME'], x['TIMESTAMP']]))
test_data = test_target.merge(label_test_df.drop_duplicates(['timestamp', 'label'])[['timestamp', 'label']], on='timestamp')
test_data['label'] = test_data['label'].astype('category').cat.codes #2: 주의, 0:경고, 1: 정상test data도 label값을 불러와 카테고리형으로 바꾸어 줍니다.

(4) predict
yy = test_data['label']
XX = test_data.iloc[:, rf1.feature_importances_.argsort()[::-1][:10]]
predicted = rf2.predict(XX)from sklearn.metrics import confusion_matrix
cm = pd.DataFrame(confusion_matrix(predicted, yy), columns=['경고', '정상', '주의'], index=['경고', '정상', '주의'])
plt.rc('font', family='NanumBarunGothic')
plt.figure(figsize=(10,8))
sns.heatmap(cm, annot=True, cmap=plt.cm.Blues, fmt='d')
plt.show()
정상을 살짝 헷갈려 하긴하지만 꽤 괜찮은 모델성능을 보이고 있다.
'개발새발 > 데이터분석' 카테고리의 다른 글
| [Python] 제주도 도로 교통량 분석 및 예측모델(XGB, folium) (1) | 2024.02.19 |
|---|---|
| [Python] 가스 공급량 분석 및 예측 모델(시계열분석) (0) | 2024.02.13 |
| [Python] 신용카드 이상거래 탐지 모델(Undersampling, Oversampling) (2) | 2024.02.02 |
| [Python] E-commerce 행동 데이터 분석(RFM기반, Kmeans) (1) | 2024.01.31 |
| [Python] 어떤 동물이 빨리 입양될까?(Logistic Regression, scikit-learn, tensorflow) (3) | 2024.01.29 |