천연가스를 수입하여 회사에 공급하는 비즈니스를 할때
너무 많이 수입하여 재고량이 많아지면 저장/관리 비용이 증가하고,
너무 적게 수입하면 계약위반에 따른 위약금, 가스 미공급으로 인해 다양한 손해배상이 발생할 수 있으므로
적정량의 수입이 필요하다.
1. Data Info Check
한국 가스공사 시간별 공급량 데이터를 사용하였습니다
(1) Data load

연월일과 시간, 구분은 회사구분코드, 공급량이 나와있는 데이터 입니다.
2013년도부터 2018년도까지 6개년도의 일별/시간별 데이터가 있습니다.
시간은 1~24로 구분되어있으나 보통 00시부터 23시로 보기 때문에 -1을 해서 사용하겠습니다:D
df.dtypes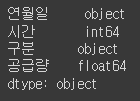
연월일도 문자형태로 되어있어 datetime으로 변환하겠습니다
pd.to_datetime(df['연월일'])
df['date'] = pd.to_datetime(df['연월일'] + ':' + df['시간'], format='%Y-%m-%d:%H')
df.index = pd.DatetimeIndex(df['date'])
df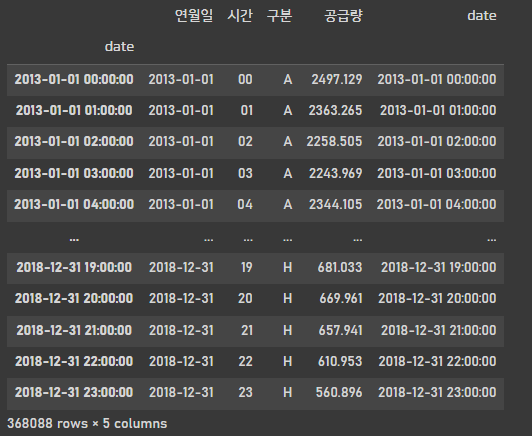
시계열 데이터를 분석하기 위해 날짜 형식으로 변환해주었습니다.
df = df.drop(['연월일', '시간', 'date'], axis=1)필요없는 데이터는 메모리를 위해 삭제!
df = df.reset_index()
df
시계열 데이터는 순서가 중요하기 때문에 인덱스 리셋해서 다시 설정해주었습니다.
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(24,10))
sns.lineplot(x = "date", y = "공급량", data=df, hue="구분")
sns.set(style='dark',)
#plt.show()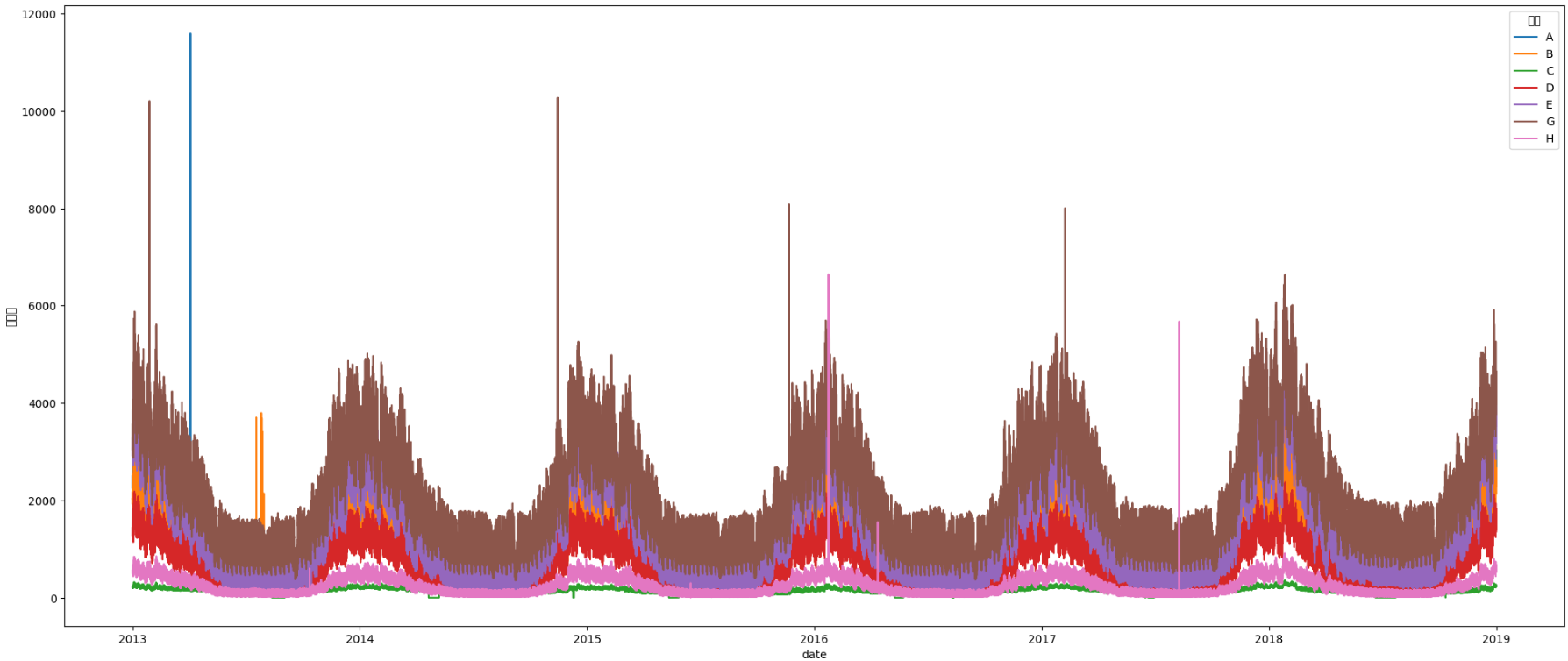
전체 데이터를 그래프로 그려보았으나 중간중간 튀는 데이터가 있어서 한눈에 보기에는 어려움이 있는 듯 합니다.
2. Data Readiness Check
수집된 데이터들의 기본 정보들을 확인하고 outlier를 어떻게 할지 고민합니다.
def IQR(df, col):
describe = df.describe()['공급량']
Q1 = describe['25%']
Q3 = describe['75%']
IQR = Q3 - Q1
higher = Q3 + IQR*3
return higher
def plot_df(df, company_code):
print(df[df['구분']==company_code].describe()['공급량'])
higher = IQR(df[(df['구분']==company_code)], '공급량')
fig, ax = plt.subplots(1,1,figsize=(18,12))
sns.lineplot(x = "date", y = "공급량", data=df[(df['구분']==company_code)], ax=ax).axhline(y=higher, color='red')
plt.show()먼저 분위수를 선택해서 outlier로 주고 그래프로 확인했습니다.
더 자세하게 알아보기 위해서 회사구분코드별로 그래프를 그려보겠습니다.
plot_df(df, 'A')
A회사의 경우는 한개만 outlier밖으로 벗어난것을 확인할 수 있습니다.
outlier가 많지 않아 삭제하는 것이 좋을 것 같습니다.
plot_df(df, 'B')
B회사는 outlier는 크게 보이지 않으나 2013년도 여름에 갑자기 치솓는게 보입니다.
plot_df(df, 'C')
C회사는 outlier는 보이지 않으나.
중간중간 데이터값이 아래로 확 떨어지는게 보입니다. 다른값으로 채워넣는게 좋을 것같습니다.
plot_df(df, 'D')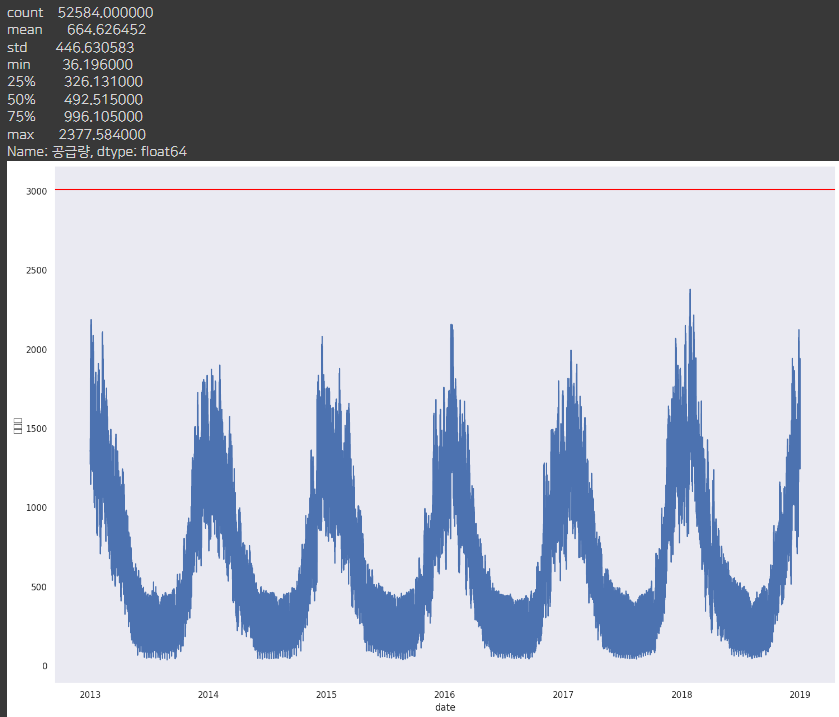
D회사는 크게 이상치 없음
plot_df(df, 'E')
E회사도 이상치가 크게 없어보임.
plot_df(df, 'G')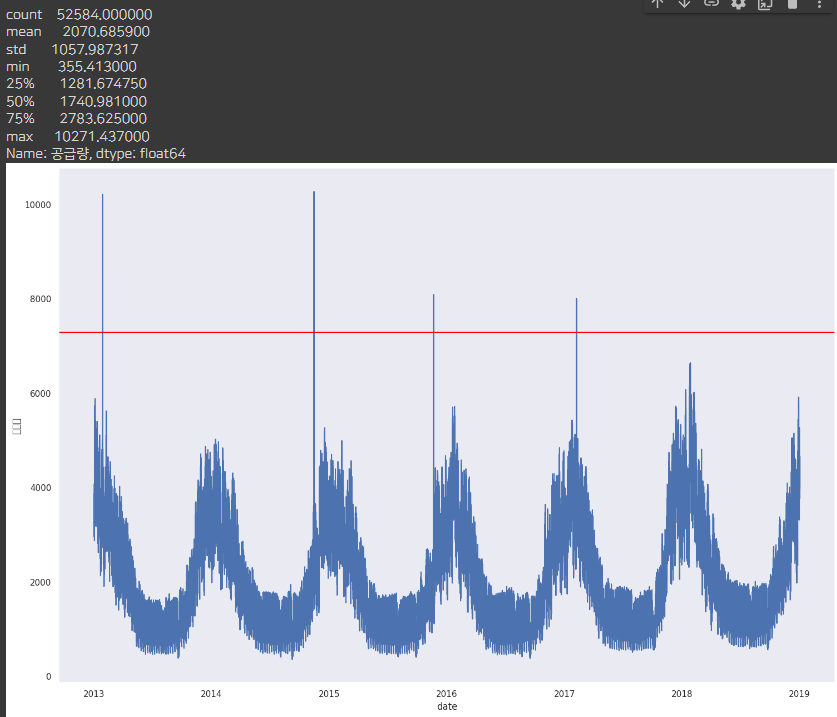
G회사는 중간중간 outlier가 있어서 데이터 전처리가 필요해 보입니다.
plot_df(df, 'H')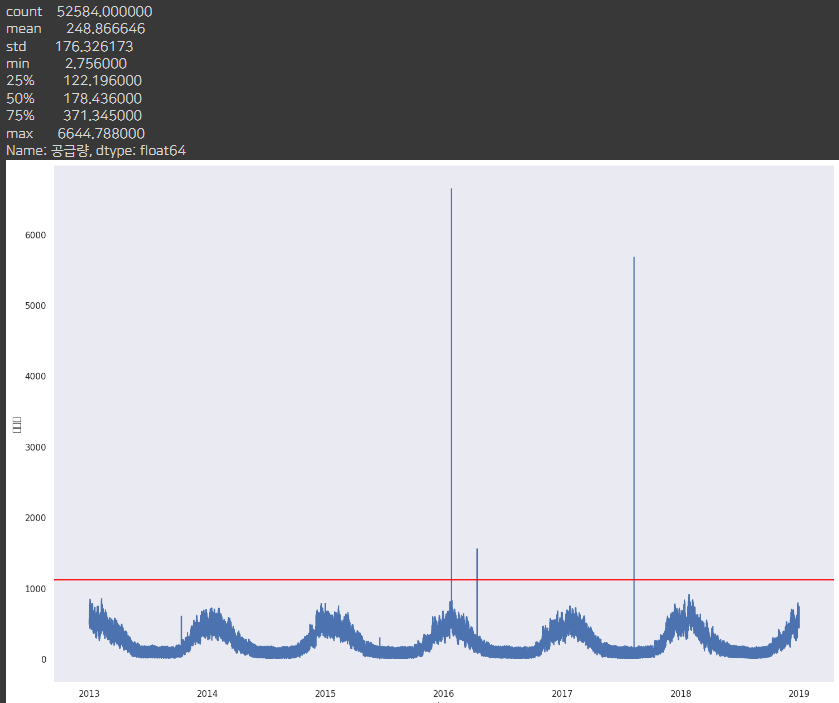
H회사의 경우도 outlier가 많은 것은 아니나
outlier때문에 척도가 바뀌기 때문에 삭제하는 쪽으로 방향을 잡아볼 예정입니다.
3. Feature Engineering
def IQR(df, col):
describe = df.describe()['공급량']
Q1 = describe['25%']
Q3 = describe['75%']
IQR = Q3 - Q1
higher = Q3 + IQR*3
return higher
def plot_del_outlier_df(df, company_code):
print(df[df['구분']==company_code].describe()['공급량'])
higher = IQR(df[(df['구분']==company_code)], '공급량')
fig, ax = plt.subplots(1,2,figsize=(26,8))
sns.lineplot(x = "date", y = "공급량", data=df[(df['구분']==company_code)], ax=ax[0]).axhline(y=higher, color='red')
sns.lineplot(x = "date", y = "공급량", data=df[(df['구분']==company_code) & (df['공급량'] < higher)], ax=ax[1])
plt.show()
return df[(df['구분']==company_code) & (df['공급량'] < higher)]중간중간 튀는 값들을 삭제하기 위해서 함수를 작성했습니다.
outlier가 있을때와 삭제하고 난 다음의 그래프를 같이 그려서 비교해 보겠습니다.
df_A = plot_del_outlier_df(df, 'A')
혼자 튀는 값이 있던 A회사 outlier삭제.
df_B = plot_del_outlier_df(df, 'B')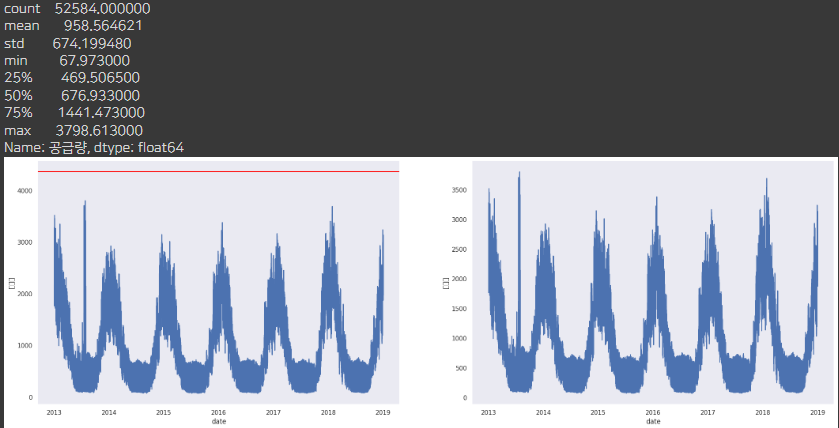
df_C = plot_del_outlier_df(df, 'C')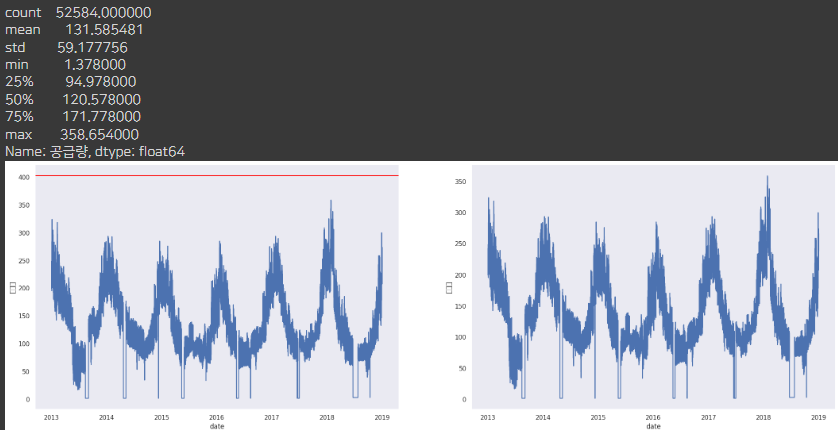
C회사의 경우는 outlier는 없었으나 밑으로 가는 이상한 데이터가 있어서
계속 해서 처리 해보겠습니다.
df_D = plot_del_outlier_df(df, 'D')
df_E = plot_del_outlier_df(df, 'E')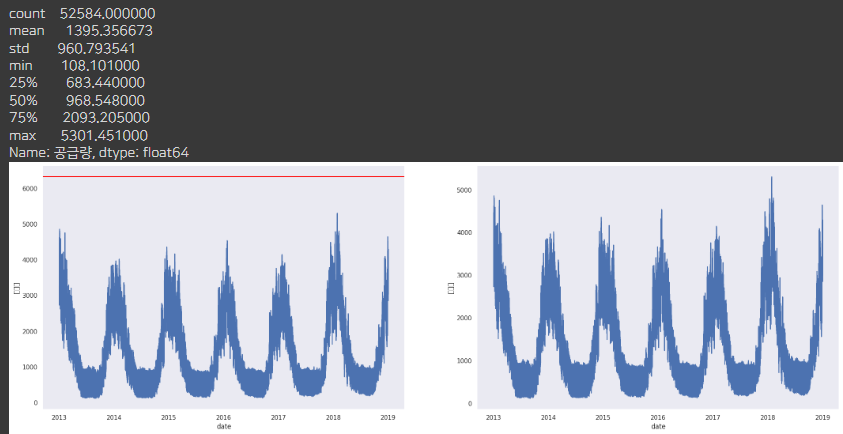
outlier가 없던 B,D,E 회사의 데이터는 동일 합니다.
df_G = plot_del_outlier_df(df, 'G')
df_H = plot_del_outlier_df(df, 'H')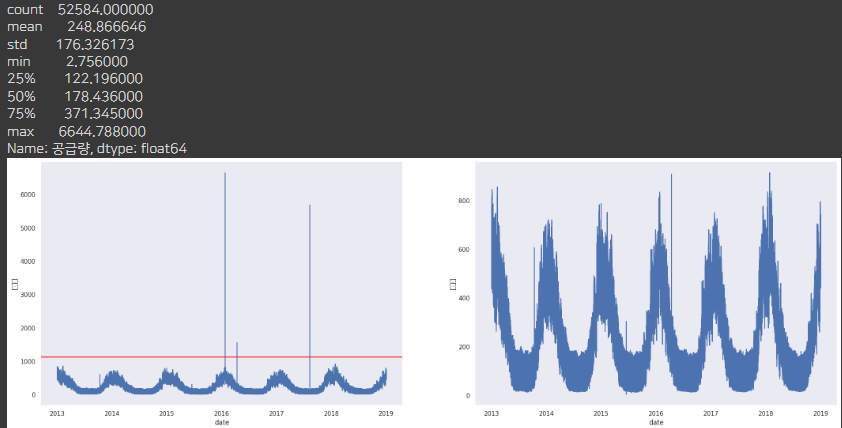
outlier가 있던 G,H 회사는 outlier를 제거하고 나니 다른 회사와 비슷한 양상의 그래프가 보입니다.
가스는 보통 겨울에 많이 사용해서, 계절성을 띄는 시계열 데이터에 속합니다.
# 이상치 구간에 대한 보간 작업을 위한 NaN으로 대치
df_C.loc[(df_C['공급량'] < 10), '공급량'] = np.nan
# 이상치 구간을 보간치로 보정
df_C[['date','공급량']].set_index('date').interpolate().plot(figsize=(18,6))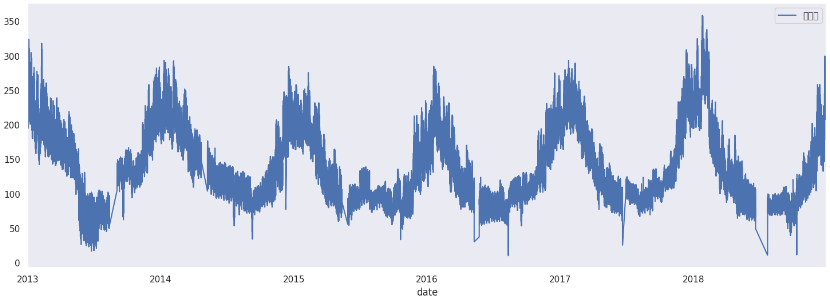
C회사의 이상했던 데이터를 보간작업을 하기 위해 NaN으로 대치해서 처리해주었습니다.
선형구간이라고 치고 interpolate로 보간작업을 진행하였습니다.
df_C = df_C[['date','공급량']].set_index('date').interpolate()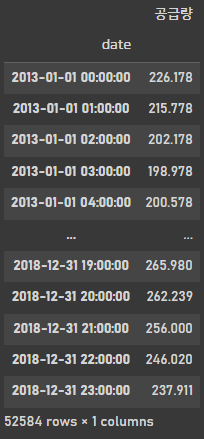
4. Modeling
%pip install mxnet gluonts --quiet
from gluonts.dataset.common import ListDataset
from gluonts.dataset.field_names import FieldName
from gluonts.mx.model.deepar import DeepAREstimator
from gluonts.mx.trainer import Trainer
from gluonts.evaluation.backtest import make_evaluation_predictions
from gluonts.evaluation import Evaluator
from pathlib import Path
import jsondef plot_prob_forecasts(ts_entry, forecast_entry):
prediction_intervals = (90.0, 50.0)
legend = ["Consumption", "observations", "median prediction"] + [f"{k}% prediction interval" for k in prediction_intervals][::-1]
fig, ax = plt.subplots(1, 1, sharex=True, sharey=False, figsize=(20, 7))
ts_entry.plot(ax=ax)
forecast_entry.plot(prediction_intervals=prediction_intervals, color='g')
plt.grid(which="both")
plt.legend(legend, loc="upper left")
plt.show()회사 구분 코드별로 시계열데이터를 확인하기 위해서 함수를 하나 작성해주었습니다.
def predict_next_year(df):
# 먼저, 입력된 DataFrame을 시간 단위에서 -> 일 단위로 합계를 구한다. (Transform)
df['year'] = df['date'].dt.year
df['month'] = df['date'].dt.month
df['day'] = df['date'].dt.day
df = df.groupby([df['year'], df['month'], df['day']]).sum().reset_index()
# 2017년까지 데이터
train_df = df[:1826]
# 2018년 데이터
test_df = df[1826:]
train_ds = ListDataset([{FieldName.TARGET: train_df[['공급량']].values.flatten(),
FieldName.START: pd.Timestamp("2013-01-01 00:00:00", freq='D')
}],
freq='D')
test_ds = ListDataset([{FieldName.TARGET: test_df[['공급량']].values.flatten(),
FieldName.START: pd.Timestamp("2018-01-01 00:00:00", freq='D')
}],
freq='D')
# 시계열 예측 알고리즘 중 가장 많이 사용되고 있는 DeepAR(AutoRegression) 사용
estimator = DeepAREstimator(
# 데이터의 주기(D, W, M, Y)
freq='D',
# Trainer, cpu | gpu, 학습 반복 횟수,
trainer=Trainer(ctx="cpu", epochs=5, learning_rate=1E-3, hybridize=True, num_batches_per_epoch=100,),
# Deeplearning layer 수
num_layers=4,
# lstm 셀 갯수
num_cells=40,
context_length=360,
cell_type='lstm', #gru
# 얼마의 기간에 대해서 예측할 것인가
prediction_length=360
)
# 학습
predictor = estimator.train(train_ds)
forecast_it, ts_it = make_evaluation_predictions(
dataset=test_ds,
predictor=predictor,
num_samples=10,
)
forecasts = list(forecast_it)
tss = list(ts_it)
ts_entry = tss[0]
test_ds_entry = next(iter(test_ds))
forecast_entry = forecasts[0]
plot_prob_forecasts(ts_entry, forecast_entry)
print(f"Number of sample paths: {forecast_entry.num_samples}")
print(f"Dimension of samples: {forecast_entry.samples.shape}")
print(f"Start date of the forecast window: {forecast_entry.start_date}")
print(f"Frequency of the time series: {forecast_entry.freq}")
evaluator = Evaluator(quantiles=[0.1, 0.5, 0.9])
agg_metrics, item_metrics = evaluator(tss, forecasts)
print(json.dumps(agg_metrics, indent=4))회사구분코드별로 2017년도까지의 데이터로 학습하고 2018년도를 예측하기 위해서 함수를 작성해주었습니다.
시간단위로 그래프를 그릴시에 너무 빼곡하기 때문에 일단위로 합쳐서 그래프를 그려주었습니다.
predict_next_year(df_A)
데이터의 양이 꽤 많아서 한번돌때마다 5분정도씩 시간이 소요되었습니다.
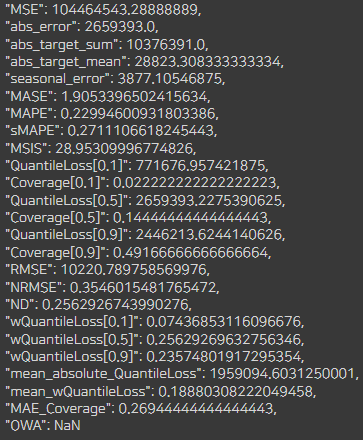
A회사의 경우 결측치 하나의 값을 삭제해주었고, 에러는 약 22%정도 나왔습니다.
초반 트랜드는 잘 맞추는듯 하더니 갈수록 에러가 커지는 양상이 보입니다.
predict_next_year(df_B)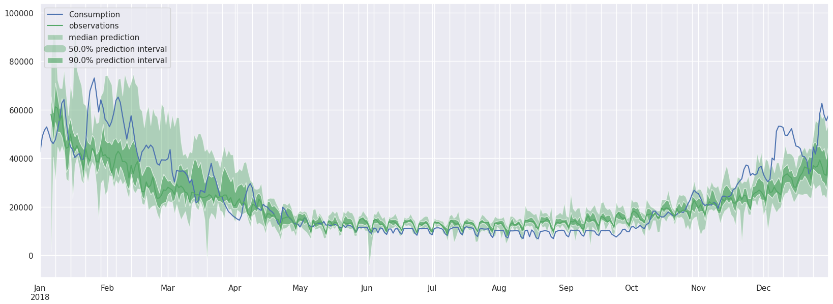

B회사도 별다른 결측치가 없었기 때문에 24%정도의 에러가 나왔습니다.
df_C = df_C.reset_index()
df_C['date'] = pd.DatetimeIndex(df[df['구분']=='C']['date'])
predict_next_year(df_C)

가장 걱정되었던 C회사는 살펴보니 역시 좋지 못한 값이 나왔습니다.
100%가 넘는 에러. 그래프로만 봐도 두드러지게 나타납니다.
다른쪽으로 보간작업을 하는 방법을 더 연구해볼 필요가 있어보입니다.
predict_next_year(df_D)
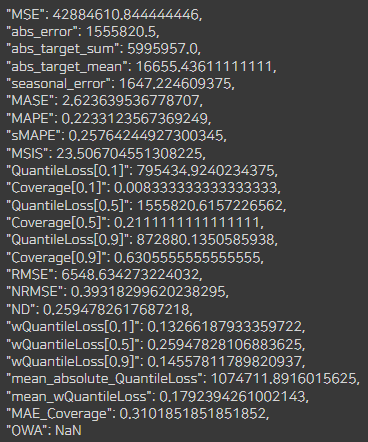
D회사는 앞선 A,B회사와 비슷하게 22%정도의 에러가 보입니다.
중간에 확 떨어지는 데이터가 있어 척도가 많이 떨어져 그래프상으로는 가장 흡사해보이지만
확대해서 보면 A,B회사와 흡사한 그래프입니다.
predict_next_year(df_E)
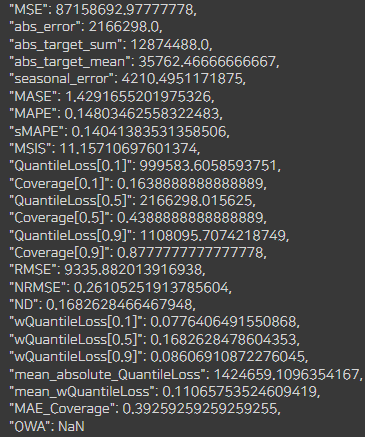
predict_next_year(df_G)

E랑 G회사는 크게 결측값도 없고 데이터가 깨끗해서
에러값이 13~14%정도로 가장 낮게 나왔습니다.
predict_next_year(df_H)

결측치를 몇개 삭제하였더니 H회사는 에러값이 32%로 어느정도 나왔습니다.
# 전체 회사에 대한 예측
def predict_next_year_total(df):
df['year'] = df['date'].dt.year
df['month'] = df['date'].dt.month
df['day'] = df['date'].dt.day
df = df.groupby([df['year'], df['month'], df['day']]).sum().reset_index()
train_df = df[:1826]
test_df = df[1826:]
train_ds = ListDataset([{FieldName.TARGET: train_df[['공급량']].values.flatten(),
FieldName.START: pd.Timestamp("2013-01-01 00:00:00", freq='D')
}],
freq='D')
test_ds = ListDataset([{FieldName.TARGET: test_df[['공급량']].values.flatten(),
FieldName.START: pd.Timestamp("2018-01-01 00:00:00", freq='D')
}],
freq='D')
estimator = DeepAREstimator(
# 데이터의 주기(D, W, M, Y)
freq='D',
# Trainer, cpu | gpu, 학습 반복 횟수,
trainer=Trainer(ctx="cpu", epochs=5, learning_rate=1E-3, hybridize=True, num_batches_per_epoch=100,),
# Deeplearning layer 수
num_layers=4,
# lstm 셀 갯수
num_cells=40,
context_length=360,
cell_type='lstm', #gru
# 얼마의 기간에 대해서 예측할 것인가
prediction_length=360
)
predictor = estimator.train(train_ds) #3.27
forecast_it, ts_it = make_evaluation_predictions(
dataset=test_ds, # test dataset
predictor=predictor, # predictor
num_samples=10, # number of sample paths we want for evaluation
)
forecasts = list(forecast_it)
tss = list(ts_it)
ts_entry = tss[0]
test_ds_entry = next(iter(test_ds))
forecast_entry = forecasts[0]
plot_prob_forecasts(ts_entry, forecast_entry)
print(f"Number of sample paths: {forecast_entry.num_samples}")
print(f"Dimension of samples: {forecast_entry.samples.shape}")
print(f"Start date of the forecast window: {forecast_entry.start_date}")
print(f"Frequency of the time series: {forecast_entry.freq}")
evaluator = Evaluator(quantiles=[0.1, 0.5, 0.9])
agg_metrics, item_metrics = evaluator(tss, forecasts)
print(json.dumps(agg_metrics, indent=4))회사별 말고도 전체 사용량을 기준으로 모델링을 해보았습니다.
predict_next_year_total(df)

각 회사마다의 특성이 있어서 그런가 전체데이터를 사용할때에 가장 좋지 못한 성능을 보입니다.
이런경우에는 회사구분코드별로 나누는 것이 모델을 만들기에 더 좋은 판단이라고 생각합니다.
'개발새발 > 데이터분석' 카테고리의 다른 글
| [Python] 제주도 도로 교통량 분석 및 예측모델(XGB, folium) (1) | 2024.02.19 |
|---|---|
| [Python] 공조기기 전력 사용 상태 분석(json파일 처리) (1) | 2024.02.07 |
| [Python] 신용카드 이상거래 탐지 모델(Undersampling, Oversampling) (2) | 2024.02.02 |
| [Python] E-commerce 행동 데이터 분석(RFM기반, Kmeans) (1) | 2024.01.31 |
| [Python] 어떤 동물이 빨리 입양될까?(Logistic Regression, scikit-learn, tensorflow) (3) | 2024.01.29 |